•admin•7 Minuten
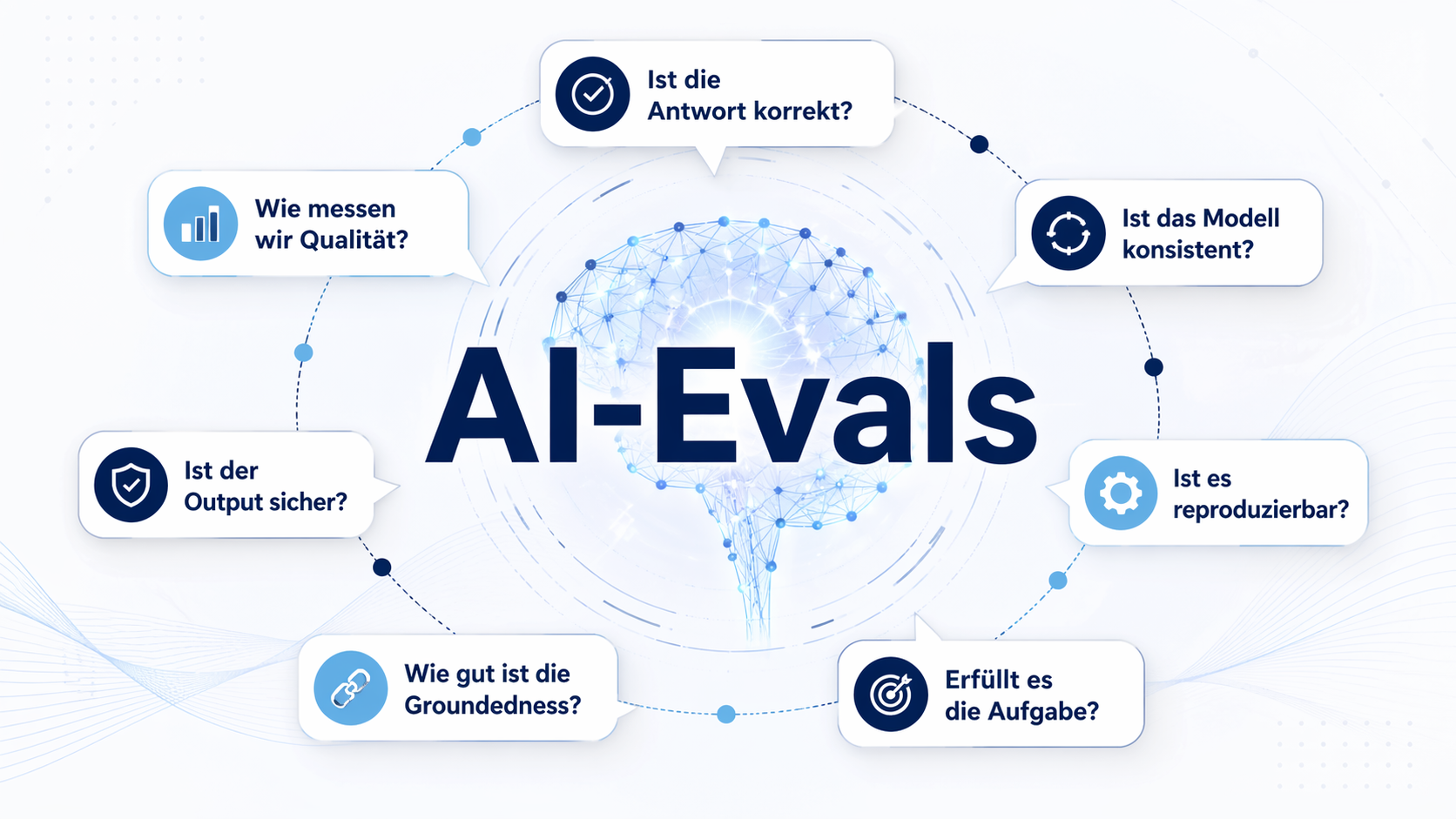
AI Evals: Fünf Dimensionen für produktive KI-Systeme
Im laufenden Betrieb Ihres KI-Systems fallen Ihnen drei Dinge auf. Der Token-Verbrauch steigt von einem Sprint zum nächsten um 40 %, ohne dass eine Konfigurationsänderung das erklären würde. Nach einem Prompt-Update verändert sich die Antwortqualität spürbar; das Team empfindet sie als schlechter, kann aber nicht benennen, warum. Und Ihr RAG-System liefert Aussagen, die in keinem […]
Mehr lesen→