Künstliche Intelligenz (KI) hat das Potenzial, Unternehmen in einer Vielzahl von Sektoren zu transformieren. Aber dieser Transformationsprozess ist kein leichtes Unterfangen. Ein zentraler Aspekt der Einführung von KI, der häufig übersehen wird, ist die Säuberung der Daten, die zur Fütterung der intelligenten Modelle verwendet werden. Die Datenbereinigung in KI-Projekten oder auch Data Cleaning genannt stellt viele Unternehmen vor enorme Herausforderungen, da sie grundlegende Änderungen der Unternehmenskultur und der Arbeitsweisen erfordert.
Die Bereinigung der Daten ist ein wesentlicher Schritt in der Vorbereitung von KI-Projekten. Neben allgemeinen Herausforderungen für KI-Projekte im Unternehmen, umfasst der Prozess der Datenbereinigung die Entfernung von Fehlern und Inkonsistenzen in Daten, um ihre Qualität zu verbessern. Doch einfacher gesagt als getan: Die Datenbereinigung ist ein komplexer Prozess, der sowohl technisches Know-how als auch ein tiefes Verständnis des Geschäfts und seiner Datenquellen erfordert.
Eine der größten Herausforderungen in der Datenbereinigung ist die Beseitigung technologischer Schranken. In vielen Unternehmen sind die Daten in verschiedenen Systemen gespeichert und weisen unterschiedliche Formate und Strukturen auf. Dies erschwert die Identifizierung und Korrektur von Fehlern und Inkonsistenzen in den Daten.
Eine weitere Herausforderung besteht darin, eine Unternehmenskultur zu schaffen, die die Bedeutung von Datenqualität und -bereinigung anerkennt. Dies erfordert eine Veränderung in der Denkweise des gesamten Unternehmens – von der Unternehmensführung bis hin zu den Datenanalysten und IT-Teams.
Technologische Hürden sind ein zentrales Problem bei der Datenbereinigung in KI-Projekten. Sie manifestieren sich in verschiedenen Formen, von inkonsistenten Datenformaten bis hin zu veralteten Speichersystemen.
Datenformate und -systeme
Eine der größten Herausforderungen besteht darin, unterschiedliche Datenformate und Speichersysteme zu vereinheitlichen. Dies erfordert die Zusammenführung und Standardisierung von Daten aus vielfältigen Quellen und Formaten.
Technologie zur Überwindung
Moderne Datenintegrationswerkzeuge und Datenmanagementplattformen bieten Lösungen zur Bewältigung dieser Herausforderungen. Sie ermöglichen die effiziente Zusammenführung und Speicherung von Daten, unabhängig von deren ursprünglicher Form.
Architektur und Automatisierung
Eine robuste Datenarchitektur, oft auf Cloud-Plattformen basierend, spielt eine Schlüsselrolle bei der Datenbereinigung. Automatisierung und maschinelles Lernen reduzieren den Aufwand und verbessern die Datenqualität.
Notwendigkeit für den Erfolg
Die Überwindung technologischer Hürden in der Datenbereinigung ist unerlässlich für den Erfolg von KI-Projekten. Durch den gezielten Einsatz von Werkzeugen und Plattformen können Unternehmen ihre Datenqualität sichern und ihre KI-Ziele effektiv erreichen.
Die Verbesserung der Datenbereinigungsprozesse in KI-Projekten erfordert sowohl technologische als auch kulturelle Veränderungen. Technologisch gesehen sollten Unternehmen in Tools und Lösungen investieren, die eine effektive Datenbereinigung ermöglichen. Auf der kulturellen Seite ist die Schaffung einer datengesteuerten Unternehmenskultur entscheidend. Mitarbeiter auf allen Ebenen müssen die Bedeutung von Datenqualität verstehen und den Wert sehen, den eine effektive Datenbereinigung zum Erfolg der KI-Projekte des Unternehmens beiträgt.
Die Datenbereinigung in KI-Projekten stellt zweifellos eine Herausforderung dar. Aber es ist eine Herausforderung, die Unternehmen annehmen müssen, wenn sie das volle Potenzial von KI ausschöpfen wollen. Durch die Verbesserung der Datenbereinigungsprozesse und die Förderung einer datengesteuerten Unternehmenskultur können Unternehmen ihre KI-Projekte sicher und erfolgreich implementieren. Nehmen Sie heute noch die Herausforderung an und beginnen Sie damit, die hohe Qualität Ihrer Daten zur Priorität zu machen.
Bei der Anwendung von Künstlicher Intelligenz (KI) in Unternehmen ist ein Aspekt von entscheidender Bedeutung, der oft übersehen wird: die Qualität der verwendeten Daten. Besonders in der heutigen datengesteuerten Welt kann die Datenqualität den Unterschied zwischen einem erfolgreichen KI-Projekt und einem gescheiterten Experiment ausmachen. Schauen wir uns Daten unter dem Mikroskop an…
Neben beispielsweise unterschiedlichen Consumer-Datentypen, welche die Beziehungen zwischen den Akteuren darstellen (First-, Second- und Third-Party Data), ist jedoch Datenqualität an sich ein komplexer Begriff, der verschiedene Dimensionen umfasst. Dies sind Genauigkeit, Aktualität, Relevanz, Vollständigkeit und Konsistenz. Jede dieser Komponenten spielt eine entscheidende Rolle für die Effektivität von KI-Systemen.
Genauigkeit, Aktualität, Relevanz, Vollständigkeit und Konsistenz sind also die Eckpfeiler guter Datenqualität. Aber was passiert, wenn diese Grundprinzipien ignoriert werden? Schlechte Datenqualität kann zu Fehlinterpretationen führen, die sich negativ auf Unternehmensentscheidungen auswirken. Sie könnte eine ineffektive Ausrichtung von Ressourcen zur Folge haben oder sogar zu einem Verlust des Vertrauens in KI-Initiativen führen.
Wie sagt das Sprichwort? „Shit in, Shit out“. Wenn die Qualität Ihrer Daten mangelhaft ist, können Sie auch von Ihrer KI keine hochwertige Performance erwarten. Eine sorgfältige Überprüfung und Verbesserung der Datenqualität ist daher unerlässlich für den Erfolg Ihrer KI-Initiative. Schließlich kann die Anwendung von KI auf hochwertige Daten dazu beitragen, wertvolle Erkenntnisse zu gewinnen, fundierte Entscheidungen zu treffen und eine effizientere Betriebsführung zu gewährleisten.
Diese Schritte helfen dabei, die Datenqualität hochzuhalten, sodass Sie das Potential Ihrer KI-Projekte voll ausschöpfen können. Erinnern Sie sich daran, dass Datenqualität kein einmaliges Projekt ist, sondern eine ständige Aufgabe, die regelmäßige Pflege und Aufmerksamkeit erfordert.
Was Ihnen jetzt noch fehlt, ist ein Data Quick Check? Sprechen Sie uns gern an! Epicinsights unterstützt Sie mit einem unverbindlichen Check Ihrer Daten. Für mehr Infos rund um das Thema KI und zu den einzelnen Schritten Ihrer Potenzialanalyse stehen wir gern bereit.
Künstliche Intelligenz (KI) entwickelt sich in einem atemberaubenden Tempo. Für Unternehmen, die in diesem Bereich aktiv sind oder planen, in ihn einzusteigen, stellt sich daher zwangsläufig die Frage, wie sie ihre Investitionen und Entwicklungen zukunftssicher gestalten können. Kann man Zukunftssicherheit in der KI-Entwicklung gewährleisten, wenn sich Technologien so schnell ändern?
Sie sollten über folgende These nachdenken: Das Bestreben nach Zukunftssicherheit, in der sich rasch entwickelnden Welt der KI, könnte unrealistisch sein.
Denn angesichts der rasanten technologischen Veränderungen und des hohen Innovationstempos im Bereich der KI ist es schwierig, Entscheidungen zu treffen, die auch in einigen Jahren noch Bestand haben werden.
Das bedeutet jedoch keinesfalls, dass Unternehmen jetzt resignieren und sich dem Lauf der Dinge hingeben sollten. Sie sollten einen flexiblen und adaptiven Ansatz verfolgen, der es ermöglicht, auf Veränderungen zu reagieren. Statt zu versuchen, spezifische Technologieentscheidungen zukunftssicher zu machen, empfiehlt sich ein so genannter Toolbox-Ansatz. Nach diesem Ansatz betreut auch epicinsights erfolgreich Unternehmen. Dieser beinhaltet mehrere KI-Lösungen in Betracht zu ziehen und eine flexible Architektur aufzubauen. Diese kann unterschiedliche Anwendungen und Ansätze integrieren und bietet so die Möglichkeit, die KI-Strategie je nach Bedarf und technologischer Entwicklung anzupassen.
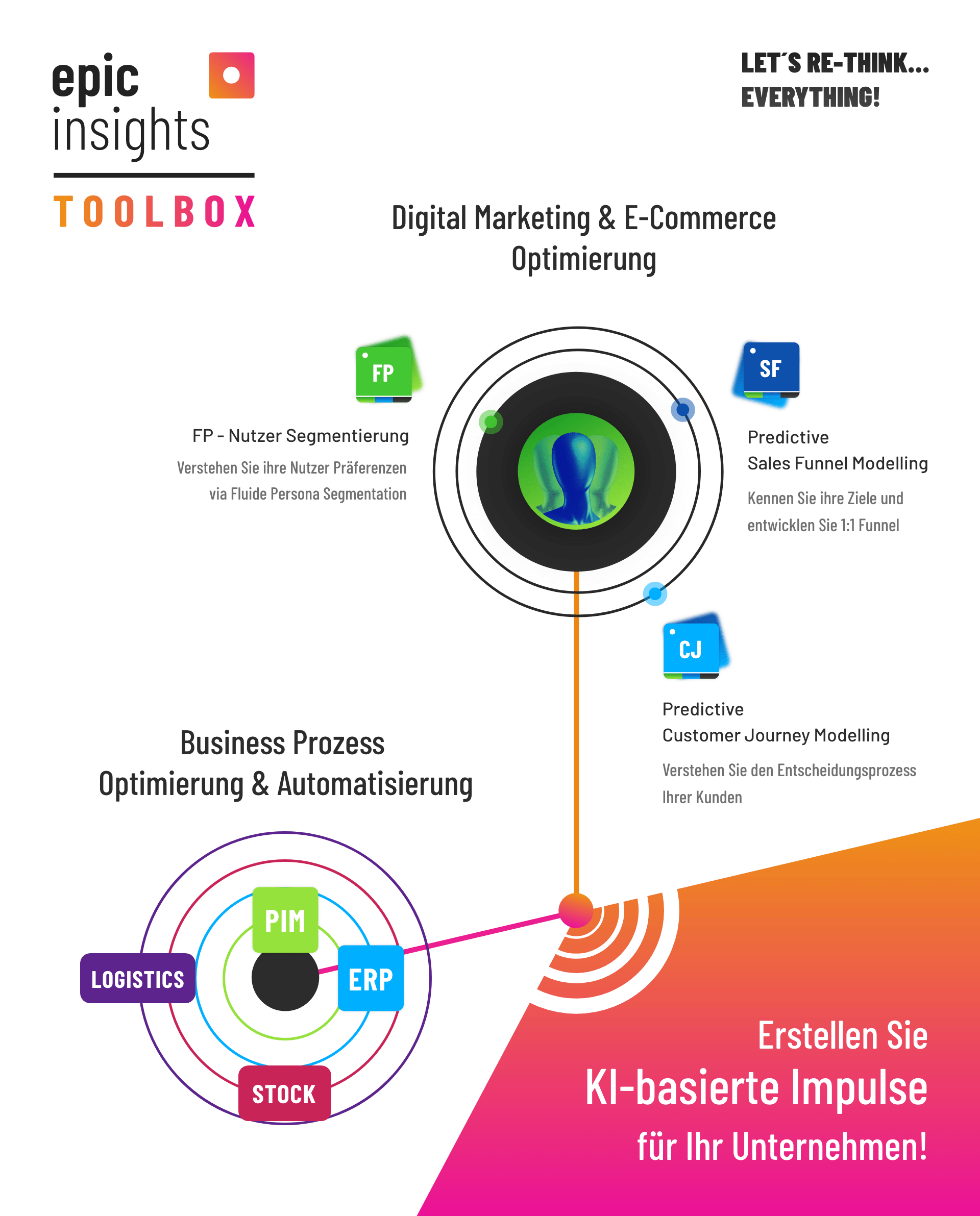
Die Wichtigkeit einer starken Governance und Lenkungsstruktur in der KI-Entwicklung darf dabei nicht vernachlässigt werden. Klare Leitplanken und eine robuste Managementstruktur können sicherstellen, dass KI-Initiativen in die richtige Richtung gehen und Risiken minimiert werden. Es ist eine dynamische und fortwährende Aufgabe, eine solche Architektur zu entwickeln und zu pflegen. Aber eine solche Investition wird auf lange Sicht erhebliche Vorteile bringen.
Letztlich ist die Zukunftssicherheit in der KI-Entwicklung vielleicht weniger eine Frage des richtigen Vorhersagens von Trends und Technologien, sondern vielmehr eine Frage der richtigen Einstellung und Struktur. Mit Flexibilität, Anpassungsfähigkeit und einer starken Governance können Unternehmen sicherstellen, dass sie in der sich schnell verändernden Welt der KI nicht den Anschluss verlieren. Nach den Bedürfnissen des Unternehmens entwickelt epicinsights Individuelle Lösungsansätze. Wir unterstützen als kompetenter Partner für alle Themen rund um Künstliche Intelligenz.
Sollten sie ihre eigenen KI-Modelle entwickeln oder ein fertiges Modell von einem Anbieter kaufen? Viele Unternehmen stehen vor dieser entscheidenden Frage.
Diese Entscheidung ist für KI-Modelle nicht einfach zwischen Schwarz und Weiß zu treffen. Es gibt viele Faktoren, die berücksichtigt werden müssen, bevor man sich für einen Weg entscheidet. Zu diesen zählt die Geschäftsstrategie des Unternehmens, die Risikotoleranz und die entstehenden Kosten. Jedoch auch, inwieweit die vorhandene Datensammlung und die Datenanalyse Methoden des Unternehmens genutzt und in den Dienst der KI gestellt werden kann.
Die „Make or Buy“ Frage gibt es bereits seit langer Zeit im KI-Bereich. Für mächtige Foundation Models wie GPT oder Bard stellt sich die Frage für die meisten Unternehmen nicht wirklich Die Investitionen und Risiken solcher Vorhaben sind für Unternehmen nahezu unlösbar. Ganz zu schweigen von den enormen Datenmengen, die zum Trainieren dieser mächtigen Transformer-Modelle notwendig sind. Setzen wir auf einer abstrakten Ebene an, um uns dem Problem zu nähern.
Als strategischer Begleiter von Unternehmen und KI-Teams haben wir in mehr als 8 Jahren Erfahrungen und relevantes Wissen gesammelt, um Fragen zur „Make or Buy“ Entscheidung zu beantworten. In unserer Beitragsreihe klären wir über die Vor- und Nachteile verschiedener Varianten auf.
Je nach Anwendungsfall gibt es vielerlei Arten von mathematischen Modellen, die Aufgaben des Maschinellen Lernens erfüllen. Von Bilderkennung über Vorhersagen von Zeitreihenbasierten Daten bis hin zu großen Sprachmodellen und NLP (Natural Language Processing). Das Spektrum der Methoden hinter diesen Anwendungsfeldern ist enorm gewachsen.
Entsprechend der konkreten Anforderung bringt die Entwicklung eigener KI-Modelle viele Vorteile mit sich. Unternehmen haben volle Kontrolle über den Entwicklungsprozess und können maßgeschneiderte Lösungen schaffen. Diese sind genau auf ihre spezifischen Bedürfnisse zugeschnitten und in ihre Systemlandschaft integrierbar. Dabei können unternehmenseigene Daten optimal genutzt und in das KI-Modell integriert werden, wobei die Art der Realisierung solcher Projekte exakt auf Compliance Prozesse und Datenschutzanforderungen zugeschnitten werden können.
Auf der anderen Seite stehen jedoch auch Herausforderungen. Der Entwicklungsprozess eines eigenen KI-Modells ist zeitaufwendig und ressourcenintensiv. Insbesondere erfordert die Realisierung, Pflege und Weiterentwicklung der Modelle über die Zeit hinweg fortlaufende Anstrengungen. Diese können nur mit einem festen Team von Fachleuten für maschinelles Lernen und Datenanalyse im Unternehmen oder externen Fachexperten realisiert werden.
Die andere Option, nämlich das Kaufen eines vortrainierten KI-Modells, bringt den Vorteil einer schnellen und einfachen Implementierung mit sich. Moderne Sprachmodelle haben die Tür zu innovativen Technologien, wie z.B. die Analyse von Podcasts, geöffnet.
Zu prüfen gilt hierbei, inwiefern der Anbieter auch die Wartung des Modells übernimmt, da dies dem Unternehmen viel Zeit und Mühe ersparen kann. Der Nachteil liegt jedoch darin, dass weniger Möglichkeiten zur Anpassung vorhanden sind. Vortrainierte Modelle sind oft Allzweck-Lösungen, die auf breitem Wissen aufgebaut sind. Sie sind in der Regel nicht auf die speziellen Anforderungen eines einzelnen Unternehmens zugeschnitten. Unternehmensspezifische oder gar schützenswerte Informationen sind nicht im Modell enthalten. Hier gilt es zu überlegen, inwiefern der Anbieter der Modelle entsprechende Services oder Schnittstellen anbietet, um diese unternehmensspezifischen Daten zu integrieren. Das Unternehmen seinerseits muss sich darüber klar werden, inwiefern es die Kontrolle über die Nutzung und den Schutz seiner Daten aus der Hand geben kann, wenn sich für ein externes, angepasstes Modell entschieden wird.
Die Komplexität des Themas und die individuellen Bedarfe von Unternehmen führen zu keiner eindeutigen Antwort auf die Frage. Eine derart bedeutsame Entscheidung führt oft zu Überlegungen einer Kombination aus beiden Möglichkeiten. Hybridoptionen stellen oft den optimalen Weg dar, da sie die Vorteile beider Welten vereinen. Sie kombinieren die Flexibilität der individuellen Anpassung mit der Geschwindigkeit und Effizienz vorgefertigter Lösungen. Die Herausforderung liegt darin, reibungslos unterschiedliche Systeme und Daten miteinander zu verknüpfen. Big Data Strategien scheinen in diesem Kontext also unerlässlich zu sein, um nicht blind auf willkürliche Ziele zuzusteuern. Hybridansätze ermöglichen es, bewährte KI-Modelle zu nutzen und gleichzeitig maßgeschneiderte Anpassungen über Daten und Workflow-Integrationen einzubringen. Dieser Weg kann je nach Bedarf und Datenlage zwischen Standardlösungen und individuellen Anforderungen ausbalanciert werden.
Jedes Unternehmen sollte eine eigene Strategie bereits vor dem Start in das „Abenteuer KI“ individuell erarbeiten, so dass auf die „Make or Buy“ Frage eine bedarfsgerechte Antwort gefunden wird. Die rein technische Betrachtung von datengesteuerten Lösungen, sowie strategische Fragen rund um das Geschäftsmodell, die Marktentwicklungen, das Personal, die Daten-Infrastruktur und Datensicherheit sowie die zu erwartenden Kosten spielen eine enorme Rolle.
Aber keine Sorge! Kein Unternehmen muss diesen Weg, die Implementierung von künstlicher Intelligenz, allein beschreiten. epicinsights begleitet Unternehmen in jedem Schritt ihrer KI-Initiativen seit 8 Jahren. Durch maßgeschneiderte KI-Workshops adressieren wir individuelle Bedürfnisse von Unternehmen und bauen eine Roadmap zur Beantwortung der „Make or Buy“ Frage auf.
Generative KI, jene künstliche Intelligenz, die in der Lage ist, neue Inhalte zu schaffen, wird zunehmend zum Game-Changer für Unternehmen und deren Digitalisierungsstrategie. Doch welche Markttrends bestimmen aktuell das Feld der generativen KI?
2023 gab es eine klare Bewegung hin zu großen Sprachmodellen, die von führenden Cloud-Anbietern wie OpenAI bzw. Azure, AWS und Google angeboten werden. Diese Modelle können eine nützliche Ressource für Unternehmen sein, die ihre eigenen KI-Lösungen entwickeln wollen. Sie bieten die Grundlage des allgemeinen „Weltwissens“ oder „Sprachwissens“, auf dem Unternehmen aufbauen und ihre eigenen Modelle abstimmen können. Die Nutzung künstlicher Intelligenz kann somit schneller erfolgen, da bereits entwickelte mächtige Sprachmodelle zur Verfügung stehen.
Gleichzeitig wächst die Zahl von Unternehmenssoftwarelösungen, die bereits generative KI-Funktionen eingebettet haben. Das zeigt, dass generative KI nicht mehr nur ein Feld für Forscher und Spezialisten ist, sondern zunehmend auch für den breiten Markt relevant wird. Insbesondere im Bereich der Büroproduktivität gibt es bereits viele große Anbieter, die ihre eigenen generativen KI-Lösungen anbieten. Je nach Anwendung erstrecken sich die „Add-on“-Funktionen der jeweiligen Plattformen z.B. auf die Generierung von Produktdaten (PIM/ DAM), E-Mail-Textgenerierung und Customer Support Konversation (Marketing Automation und CRM-Lösungen), Dokumentation (Notion), Bildgenerierung (Adobe Creative Cloud). Künstliche Intelligenz Agenturen unterstützen Unternehmen dabei, ihre Digitalisierungsstrategien mit KI zu realisieren.
Die Anzahl von Baukasten-Lösungen von Dritten steigt ebenfalls kontinuierlich an. Diese liefern spezifische Anwendungen für generative KI, die nur geringfügige Anpassungen erfordern, um effektiv eingesetzt werden zu können. In der Regel erweitern diese SaaS-Anbieter das Nutzungsspektrum und die Verwaltung von Anwendungsfällen über API-Anbindungen an die oben genannten GenAI-Lösungen von OpenAI, Google und Co. Dabei kann es sich um Lösungen für spezielle Probleme handeln, wie z.B. die Generierung von Bildern in speziellen Formaten oder die automatische Codierung für Websites. Hierbei werden hauptsächlich kleine gestaltbare Workflows und Templates für Prompt-Engineering mit den jeweiligen Use-Cases verknüpft. Erwähnenswert sind hierbei z.B. SaaS-Anbieter auf dem Bereich Low-Code und No-Code für Website-Erstellung, KI-Lösungen für Text-und Bilderzeugung wie Neuroflash oder poe.com. Viele SaaS-Anbieter scheinen jedoch vom Markt zu verschwinden, da ihre Lösungen große Sprachmodelle in lediglich rudimentären Frontend-Lösungen integrieren, ohne eine stabile und eigenständige Entwicklungsgrundlage zu schaffen.
Auch der Markt für Open-Source-Sprachmodelle und Trainingsdaten wächst. Portale wie Hugging Face bieten eine Plattform, auf der Entwickler tausende von offenen KI-Modellen und Datensätzen finden können. Diese sind eine wertvolle Ressource für diejenigen, die bereit sind, ihre eigenen KI-Projekte durchzuführen und dabei von der Arbeit der Community zu profitieren.
Open Source-Modelle bieten die maximale Flexibilität und stellen einen wichtigen Pfeiler für Forschung und Sicherheit bei KI-Entwicklungen dar. Große Plattformen wie Meta und Google bieten ihre Modelle Open Source an, um mit der Community diese sicher und nachhaltig weiterzuentwickeln.
Für Unternehmen stellen Open Source-Lösungen eine optimale Möglichkeit dar, ihr Wissensmanagement, Digitale Workflows und Sprachbasierte Lösungen tief in ihre Prozesse zu integrieren. Bei der Nutzung und Adaption von Open-Source KI-Modellen steht die Verwaltbarkeit der Daten, das Training von Modellen auf spezifische Wissensräume der Unternehmen sowie eine sichere und transparente Integration in die Arbeitsabläufe im Fokus von Projekten. Ebenso sollte frühzeitig über die Verwaltung dieser Modelle, deren Ressourcen-Bedarf sowie die verfügbaren Daten und deren Schutzbedarfe Klarheit geschaffen werden. Ebenso sind intern und extern verfügbare Data Science-Kompetenzen der entscheidende Hebel für die Nutzung von Open Source KI-Modellen.
All diese Trends zeigen, dass das Feld der generativen KI stark in Bewegung ist. Immer mehr Möglichkeiten eröffnen sich – aber auch immer mehr Komplexität entsteht. Die einzige Frage ist, wie man sie am besten für sich einsetzt. Unternehmen sollten evaluieren, wie KI in ihren Betriebsprozess und Geschäftsstrategien genutzt werden kann, sei es im Produktdesign, bei der Verwaltung von Lieferketten oder zur Kundenbindung. Künstliche Intelligenz wird auch zukünftig die Effizienzsteigerungen in KMUs weiter prägen. Eine Big Data Strategieberatung kann vor allem für die potenziellen Kosten eines KI-Projekts sehr hilfreich sein. Letztlich entscheidet der Use-Case über die weiteren Schritte. Wir bei epicinsights sind darauf spezialisiert, KI und Machine Learning Anwendungen individuell in enger Zusammenarbeit für die Bedürfnisse von Unternehmen zu entwickeln und Unternehmen auf dem Weg zur Erschließung von KI-Cases zu begleiten. Wir setzen auf Individualität, um den spezifischen Anforderungen und Zielen von Unternehmen gerecht werden zu können. Sprechen Sie uns gern an!
Künstliche Intelligenz (KI) ist spätestens seit 2023 ein Muss für digital ausgerichtete Unternehmen. Eine besondere Art von KI, die generative KI, kann ein Business auf ein ganz neues Level heben. Generative KI bezieht sich auf KI-Systeme, die neue Inhalte oder Daten erstellen können. Beispiele dafür sind Generative Adversarial Networks (GANs), die realistische Bilder erzeugen können, und Large Language Models (LLMs) wie GPT-4, die menschenähnlichen Text generieren können. Bei epicinsights sind wir darauf spezialisiert, KI und Machine Learning Anwendungen individuell für die Bedürfnisse von Unternehmen zu entwickeln. Ab sofort gehört generative KI ebenfalls zu unserem Portfolio. Dank individuell trainierter Large Language Models können wir generative KI zum Herzstück Ihres Unternehmens machen – ganz ohne ChatGPT & Co. Die von uns verwendeten LLMs werden sicher und datenschutzkonform in Deutschland gehostet, mit Domänenwissen Ihrer Branche trainiert und individuell auf ihr Unternehmen adaptiert.
Wir wissen, dass Sicherheit und Datenschutz bei der Nutzung von KI eine große Rolle spielen. Daher liegt hier auch unser Augenmerk. Ihre generativen KI-Modelle sind bei uns in guten Händen, denn wir hosten sie sicher auf deutschen Servern. Und weil wir wissen, dass Sie die Kontrolle über Ihre Daten behalten möchten, bieten wir eine On-Premise-Lösung sowie individuelle Rechte – und Rollensysteme für den Informationszugriff. So bestimmen Sie, wer was sehen darf. Sie haben die Kontrolle!
Sie sind der Experte / die Expertin in Ihrem Business Bereich, wir sind die KI Experten. Lassen Sie uns Hand in Hand arbeiten, um individuell trainierte Large Language Models (LLMs) zu entwickeln, die genau auf Ihre Bedürfnisse zugeschnitten sind. Diese personalisierten KI-Assistenten helfen dabei, Ihr Business noch effizienter zu machen.
Generative KI hat eine Menge zu bieten:
Entdecken Sie die Kraft der generativen KI mit unserer revolutionären Wissensmanagement-Lösung! Kein mühsames Durchsuchen von Dokumenten mehr, kein Rätselraten – nur klare, präzise Antworten, wann immer Sie sie brauchen. Mit Lösungen von epicinsights gestaltet sich Ihr Business Alltag effizienter, Sie können Kosten sparen und Kunden glücklicher machen. Also worauf warten Sie?
Dann nehmen Sie Kontakt mit uns auf, um herauszufinden, wie generative KI in Ihrem Unternehmen genutzt werden kann!
Unverbindlich Beraten lassenFür Online-Händler ist es essentiell, seine Warenbestände in Abhängigkeit von Verkaufsperformance und Lieferzeiten für Neuwaren im Blick zu behalten, um Überbestand, Warenknappheit oder gar Out-of-Stock-Situationen zu vermeiden. Die letzten Jahre waren dabei geprägt durch Lieferkettenprobleme, aber auch eine starke Nachfrage auf der Käuferseite während der Corona-Pandemie. Kurzum, das Online-Geschäft ist hochdynamisch und besonders bei einem großem Sortiment und vielen Distributionswegen ist Balancieren von Warenbeständen eine große Herausforderung. Damit die Orchestrierung zwischen Verkaufsperformance, Warenbeständen und Lagerprozessen gelingt, gibt es allerlei hilfreiche Wege, welche die Entscheidungsfindung für Warenbedarfe unterstützen sollen.
Im folgenden Beitrag soll es daher um die Einsatzmöglichkeiten von KI-basierten Assistenten gehen, die für mehr Zeit bei der Entscheidungsfindung im Warenmanagement sorgen können.
Eine Warenwirtschaftssoftware ist vor allem dafür ausgelegt, Waren- und Bestelldaten sowie Fullfillment-Prozesse zu verwalten. Sobald das Online-Geschäft eine gewisse Komplexität erreicht, kann es durchaus Sinn machen, zusätzliche Analyse- und Prognose-Fähigkeiten auf das ERP-System aufzusetzen, um die Auswertungsfähigkeit und strategische Entscheidungen zu fördern. Besonders für Multichannel Online-Händler ergeben sich hierdurch spannende neue Chancen für die Auswertung der eigenen Geschäftsaktivität. Eine Künstliche Intelligenz (kurz: KI) kann beispielsweise dafür sorgen, Absatz und Bedarfe langfristig zu prognostizieren und Empfehlungen für Warenbestellungen zu geben.
Bei allen KI-Anwendungen gilt die Grundregel: Je besser die Datengrundlage ist, mit der die Modelle trainiert werden, desto exakter ermittelt eine Forecasting-KI Prognosen und Trends für zukünftige Zeiträume. Aber auch ohne eine bereits perfekt orchestrierte Datenwelt können KI-Projekte eine gute Chance sein, um fehlerhafte oder falsche Daten, sowie systemische Probleme zu identifizieren. Händler reduzieren nachhaltig durch inkonsistente Daten ausgehende Business-Risiken, indem sie mittels KI-Modellen gezielt und in kürzester Zeit millionenfach Datensätze prüfen lassen und somit Anomalien und Inkonsistenzen aufdecken, die sonst im Verborgenen blieben. Durch die Kombination von verschiedenen Analyse- und KI-Modellen ergänzen ERP-Systeme um zuverlässige Prognosedaten, welche die Logistikprozesse im Verkauf, aber auch im Einkauf deutlich einfacher koordinierbar machen.
Eine KI kann dabei unterstützen, diese Challenges im Alltag von Multichannel Händlern zu bewältigen:
Methoden des Maschinellen Lernens bzw. KI-Modelle werden in vielen Facetten genutzt, um die Analyse und Verarbeitung von ERP-Daten zu verbessern. Die Entscheidungsfindung in Logistikprozessen und in der Verkaufsplanung unterstützt eine KI mit konkreten Berechnungen und Empfehlungen. Zur Einordnung unterscheidet man „KI“ in folgende Advanced Analytics-Bereiche:
Künstliche Intelligenz ist also dafür geeignet, Geschäftsprozesse zu automatisieren und so die Effizienz in Handelsunternehmen zu erhöhen. Dabei gilt es, die Komplexität für die Anwender zu reduzieren und aus der komplexen Datenlage heraus wichtige Informationen zusammenzutragen, um Handlungen daraus abzuleiten. Die nachhaltige Automatisierung von Prozessen im Warenwirtschaftsmanagement spart damit Zeit und Ressourcen. Sie reduziert zudem Risiken und Fehler im System, die ggf. unentdeckt blieben.
Warenwirtschaftsmanagement im großen Stil erfordert ein System mit hoher Leistung und der Fähigkeit jeden Tag viele Daten zuverlässig zu verarbeiten. Um herauszufinden, welche KI-Architektur eine optimale Ergänzung zu ihren etablierten Warenwirtschaftsprozessen ist, gilt es zunächst die Qualität, den Umfang, die Aktualität sowie die Validität Ihrer ERP-Daten zu analysieren. Dazu werden in einer sogenannten Potenzialanalyse mehrere Schritte durchlaufen, die das Datenpotenzial und die Implementierungschancen evaluiert.
Wenn alle Kriterien hinreichend erfüllt sind, erarbeitet das interdisziplinäre Team die passenden Modellierungs- und Prozess-Komponenten, welche sich in Ihre bestehenden Business-Logik und Ihre individuellen Prozesse einfügen. Das Ziel ist eine robuste, wartbare und einfach zu bedienende Lösung, mit der Anwender im Tagesgeschäft effizient arbeiten können.
Wagen Sie gemeinsam mit uns von epicinsights den Sprung. Wir führen einen unverbindlichen Quick Check Ihrer Daten durch. Für mehr Infos rund um das Thema KI in der Warenwirtschaft und zu den einzelnen Schritten Ihrer Potenzialanalyse stehen wir gern immer bereit. Sprechen Sie uns einfach an!
Castly ist eine Warenwirtschaftssoftware mit KI, die Ihre täglichen Herausforderungen im Multichannel E-Commerce lösen kann. Das Tool liefert Predictive Analytics, die Ihre komplexen Datenstrukturen intelligent aufbereitet und Bedarfsplanung zum No Brainer macht.
Es war ein Paukenschlag für die digitale Werbewelt, als Google vor wenigen Wochen das Ende des personalisierten Werbetrackings in seiner jetzigen Form ankündigte. Bis zuletzt blieb zwar noch ein etwas zwiespältiges Gefühl haften, woher der selbstlose Sinneswandel auf Google´s Cashcow-Thema wohl kam. Immerhin machte Google die Ankündigung inmitten der 3rd-Party-Cookie-Enddebatte, während Apple und Facebook gerade richtig ins Werbetracking-Battle durchstarteten. Zusammen mit der Ende Januar ebenfalls von Google angekündigten Privacy Sandbox für Chrome und mit dem allgemeinen Privacy-First-Trends bei Browsern deutet vieles auf einen schneller werdenden Strukturwandel im Markt hin. Inwiefern dieser auch zu einer stärkeren Machtzentralisierung führt, bleibt zu beobachten.
Bei stetig sinkender Datenvielfalt durch Tracking-Einschränkungen steigen gleichzeitig die Anforderungen der Kunden und Werbetreibenden in Sachen Zielgenauigkeit und KPI-Benchmarks. Wie kann das funktionieren?
Der Schlüssel steckt – wie so oft – in der algorithmischen Verwertung der Daten. Wie kann man die Auflösung der bestehenden Daten verbessern? Welche Methoden eignen sich dafür, aus einem minimalistischen Datenansatz maximale Vorhersagegenauigkeit zu ziehen? Diese Fragen beschäftigen uns seit 2015. Unsere Antwort: Fluide Personas.
Es wird also Zeit, sich die neuartige Cookie-Free-Personalisierungslösung von Google (FLoC) näher anzuschauen und mit unseren Fluiden Personas (FLuP?) zu vergleichen. Also: FloC vs. FLuP… Los geht’s:
FLoC heißt Googles System hinter dem neuen „Interest based advertising“ Konzept. FLoC bedeutet „Federated Learning of Cohorts“. Bisher wurden mittels Third-Party-Cookies alle Nutzer individuell auf Websites getrackt. Stark vereinfacht erklärt, wurden in der „alten Welt“ Herr Müller und Frau Maier also eins zu eins im Internet verfolgt. Mittels User-IDs wurden dabei ihre detaillierten Vorlieben und ihr Verhalten gespeichert. Die Tracking-Informationen wurden taxonomisch auf passende Werbetargetings gematcht. Wenn Herr Müller und Frau Maier also z.B. in der Zielgruppe der Werbetreibenden waren oder eine bestimmte Seite besucht hatten, bekamen sie eine entsprechende Anzeige ausgespielt, insofern die Tracking-ID passte.
Mit dem Federated Learning of Cohorts werden Nutzer auf Grund ihrer Eigenschaften und ihres Verhaltens auf Websites in Gruppen bzw. Kohorten eingeteilt. Dadurch sollen Einzelpersonen in der Menge verschwinden. Damit das gelingt, findet die sogenannte k-Anonymität Anwendung. Hierbei werden die Nutzer in so große Kohorten eingeteilt, bis keine Rückschlüsse mehr auf Einzelne möglich sind. Zum Schutz der User-Privatsphäre erfolgt die Verarbeitung der gesammelten Informationen geräteintern. Algorithmen auf dem Endgerät selbst weisen den Nutzer einer bestimmten Kohorte zu. Es wird also kein Cookie mehr generiert, der Daten des Users übermittelt. Laut Google haben Tests bereits gezeigt, dass Werbetreibende mit mindestens 95% der Conversions rechnen können, die sie bisher aus Third-Party-Cookies generiert haben. Mit verbesserter Datenlagen sollen sich die Ergebnisse weiter steigern.
Der datenschutzkonforme Ansatz von Fluiden Personas, wie auch von Googles FLoC geht davon aus, dass es für Personalisierung prinzipiell unnötig ist, zu wissen, wer Herr Müller und Frau Maier eigentlich sind. Stattdessen wird nach Mustern und Ähnlichkeiten im Verhalten des gesamten Schwarms gesucht, zu denen ein Nutzer am ehesten passt, um daraus Prognosen für die Zielerreichung (z.B. Kauf) abzuleiten.
Ein User wird bei FLoC genau dem Schwarmverhalten bzw. dem segmentierten Cluster zugeordnet (Gruppen-IDs), das seinem Verhalten entspricht. Statt über seine individuelle Tracking-ID wird jeder User nachträglich über die Gruppen-ID werbeseitig adressierbar. Laut Google verschwindet der User damit aus Datenschutzperspektive im Schwarm von vielen. Spannend wird weiter zu beobachten sein, wie Google den Trade-off zwischen Anonymität und Individualität setzen wird (k-Anonymität). Denn hierbei verhalten sich die Faktoren Größe einer Gruppe und Grad der Individualisierung (der Anzeigen) gegensätzlich zueinander.
Bei Fluiden Personas als Grundlage für Content-Personalisierung von Websites läuft die Personalisierung ähnlich wie bei Google. Es werden Gruppen auf Basis der Zielerreichung gebildet (z.B. Nutzer, die ein bestimmtes Produkt gekauft haben). Bei der personalisierten Content-Ausspielung werden nur Parameter des Echtzeitverhaltens beobachtet und in Relation zu den zuvor trainierten Daten aus der Gruppe verglichen, die das Ziel (z.B. Conversion) ebenfalls erreicht haben. Die jeweiligen Gruppen (bzw. Segmente) werden dabei über rein algorithmisch festgelegte Eigenschaftssammlungen des Verhaltens definiert. Es wird also auf der Gruppe trainiert und die Ergebnisse der Vorhersagen pro Individuum ausgespielt, ohne dass es wichtig ist, wer das Individuum genau ist. Auch hier geht also der Einzelne in der Gruppe unter.

Statt einen Nutzer (auf Cookie-ID-Ebene) in der Tiefe zu analysieren und auf mehr oder weniger lückenhaften Datenfragmenten eins zu eins zu bearbeiten, werden alle „oberflächlichen“ (nicht personenbezogenen) Signale und Metadaten aller Nutzer als Trainingsgrundlage der Personalisierungs-KI genutzt. Da je nach Anonymisierungslevels für den Einsatz einer künstlichen Intelligenz ggf. nicht genug Daten vom Einzelnen vorhanden sind, bedient man sich der passenden Daten aus der ähnlichsten Gruppe. Die Anreicherung mit Schwarmdaten ist wichtig, denn ohne genug „Datenfutter“ können die Algorithmen nicht sauber arbeiten. Die Gruppierung selbst läuft nur im KI-Training, in welches alle anonymisierten Verhaltensdaten einfließen und welche nicht auf das Individuum zurückführbar sind. Bei Fluiden Personas erfolgt die Entscheidung und Ausspielung des Contents komplett browserseitig und in Echtzeit. Sie hinterlässt keine Datenspuren über den Moment der Ausspielung hinaus.

Eine weitere Säule, auf der die hohe Genauigkeit unserer Personalisierungs-KI baut, ist die Datenbasis selbst. Wir haben kein eigenes technisches Ökosystem, keinen eigenen Browser, mit Millionen von Nutzern. Unsere Kunden ebenfalls nicht. Das brauchen wir auch nicht, da wir für unsere Kunden nur im Mikrokosmos ihrer Markenwelt agieren und dort sinnvolle Daten aggregieren wollen. Daher werden für Fluide Personas getreu dem Motto „Werde Herr im eigenen Datenhaus“ Daten auf First-Party-Ebene generiert. Die Vorhersage-Algorithmen laufen auf den rohen Verhaltenseigenschaften, die auf Grundlage unserer einzigartigen Tracking-Engine deutlich mehr Daten auflösen, als es herkömmliche Tools leisten. Mit 200-facher Datenauflösung im Vergleich zu am Markt gängigen Lösungen gibt es hier nochmal ordentlich Datenboost für das Training der Künstlichen Intelligenz.
Das Konzept von Fluiden Personas und Google FLoC ist also tatsächlich sehr ähnlich, auch wenn es methodisch einige Unterschiede gibt. Im Vergleich zu Google arbeiten Fluide Personas quasi auf mikroskopischem Level (a.k.a. der Website oder dem Shop einer Marke). Die algorithmische Verarbeitung ist entsprechend granular. Google muss hier Faktor 1.000.000.000 größer ansetzen. Entsprechend sind die methodischen Ansätze hinter der Philosophie verschieden und technische Vergleiche sparen wir uns lieber komplett. Die Ergebnisse von FLoC sollen lt. Google mindestens genauso gut sein, wie die „alte“ Variante. Wir wissen, dass dieser datenschutzfreundliche Ansatz im Mikrokosmos „Website“ unserer Kunden sehr gut funktioniert. Wir sind daher guter Dinge, dass Google das entsprechend auch im Scale „Internet“ schafft.
Die Personalisierungsphilosophie hinter FLuP und Googles FLoC verfolgt die gleichen Ansätze: Statt die einzelne Ameise auf dem Ameisenhaufen zu beobachten, blicken wir auf den gesamten Ameisenhaufen und versuchen Muster und Strukturen im Verhalten aller zu erkennen. Wenn ein einzelner User ein ähnliches Verhalten, wie das einer zuvor entdeckten Gruppen zeigt, werden hierüber die Zielerreichung des Individuums vorhergesagt und entsprechend passende Content-Angebote ausgespielt. Bei Fluiden Personas erfolgt dieser Abgleich mit jedem neuen, noch so kleinen Signal, das empfangen wird, während der User auf der Website surft.
Fakt ist: Personalisierung und Datenschutz sind vereinbar! Es muss Transparenz und Selbstwirksamkeit beim Nutzer hergestellt werden, darüber zu entscheiden, wie stark seine Interessen und die Vorteile eines personalisierten Angebots genutzt werden. Und es muss endlich ein Ende haben, Nutzer in statische Schubladen zu packen, aus denen es kein Entkommen gibt. Statt allein auf persönlichen Eigenschaften aufzusetzen, muss der Dynamik und Veränderlichkeit des digitalen Wesens Rechnung getragen werden. Denn: Einer guten Personalisierungsengine muss es egal sein, welches Geschlecht und Einkommen ein Nutzer hat. Der Brückenschlag zwischen Datenaggregation und Transparenz ist eine große Herausforderung, die es zu lösen gilt.
Bei FLoC sind aktuell noch viele technische und datenschutzseitige Fragen offen – besonders im Bereich Transparenz und Beeinflussbarkeit des Users selbst. Mit seinem technischen Ökosystem rund um Chrome und Android hat Google mit oder ohne FLoC, mit oder ohne Cookies, weitreichenden Zugriff auf alle Daten. Es bleibt spannend, wie sich die Entwicklungen fortsetzen, wie viel Machtverschiebung und Verdrängung der Strukturwandel für den Markt bedeuten werden. Und nicht zuletzt gilt zu beobachten, wie dieser Strukturwandel mittelfristig in der Mediawelt nachhallt und ob intelligente, unbürokratische Standards gefunden werden, die Nutzerinteressen und Werbeinteressen miteinander vereinen können.
Sie sind an eigenen KI-Projekten interessiert, wissen aber noch nicht so recht, wo und wie Sie anfangen sollen? Hier finden Sie drei Herausforderungen, die Sie dabei beachten müssen. Natürlich liefern wir Ihnen auch passende Lösungen, diese zu überwinden.
Die Integration von intelligenten Assistenten mit Hilfe von entsprechenden KI-Projekten ist mittelfristig ein unausweichlicher Schritt Richtung Digitalisierung. Gemäß einer Bitkom-Studie halten 72% der befragten Unternehmen Künstliche Intelligenz für einen relevanten Trend bei ihren Investitionsplanungen. Viele Entscheider haben hohe Erwartungen an die Technologie und dem daraus (erhofften) resultierenden Mehrwert für ihr Unternehmen. Doch wer die Sache ohne klare, datengetriebene Business Strategie und Zieldefinition angeht, verzettelt sich schnell.
Zu Beginn eines KI-Projekts muss konkret festgelegt werden, was damit erreicht werden soll. Welchen Business Impact will ich aus dem Einsatz von KI generieren? Wichtig ist hierbei vor allem, realistische Ziele zu setzen. Ebenso muss sich frühzeitig um die Skalierbarkeit und Integration Gedanken gemacht werden. Nur so können einmal erprobte Lösungen im Anschluss vertikal und horizontal um weitere Use Cases ergänzt und in die Wertschöpfung integriert werden. Für die Festlegung dieser Ziele sollten sowohl die Daten- und Analyseteams als auch entsprechende Fachbereiche und Entscheider mit einbezogen werden. Durch den Austausch zwischen Führungskräften und Datenexperten wird nicht nur sichergestellt, dass Künstliche Intelligenz am richtigen Ort Anwendung findet, sondern auch, dass Ihr KI-Projekt mit den allgemeinen Geschäftszielen konform ist.
Ohne nutzbare Datenbasis arbeitet auch der beste KI-Assistent nicht wirklich intelligent. Vor allem die Datenqualität und -quantität sind entscheidend für verlässliche Ergebnisse der Machine Learning Modelle. Viele Unternehmen besitzen diese Daten schon, die Herausforderung besteht viel mehr darin, sie zu erfassen, effektiv zu nutzen und auszuwerten. Ein Beispiel hierfür sind die sogenannten Dark Data. Eine weitere Herausforderung, vor allem für KMU, stellt zu häufig die (fehlende) Infrastruktur für die Speicherung und Verarbeitung der benötigten Datenmenge dar. Die unterschiedlichen Komponenten müssen sehr schnell aufeinander reagieren, im Problemfall ineinandergreifen und eben auch die Fallbacks kennen.
Die Lösung beider Probleme ist die Anpassung bzw. Optimierung der unternehmenseigenen Datenarchitektur. Diese muss den neuen Anforderungen gerecht werden, aber auch ausreichend flexibel sein, um mit dem Erfolg mitzuwachsen. Datenwissenschaftler und -analysten profitieren ebenfalls von diesem Infrastruktur-Update. Verbesserte Speicherlösungen, Methoden der Erfassung und Tools zur Verarbeitung von Daten erleichtern ihnen die Arbeit.
Natürlich ist auch der Kosten- und Ressourcenaufwand für solche KI-Projekte nicht zu vernachlässigen. Besonders kleine und mittlere Unternehmen operieren mit einem begrenzten Maß an finanziellen und personellen Ressourcen. Für sie ist es schwieriger, die notwendigen Mittel freizumachen. Hinzu kommt, dass oftmals Fachkräfte fehlen und damit ebenso das nötige Know-How.
Doch auch diese Hürden sind überwindbar. Kosteneffiziente Lösungen für kleinere Unternehmen sind KI-Frameworks, welche aus funktionalen, abgestimmten Einzelkomponenten bestehen, die sich auch separat integrieren lassen. Das erspart dem Unternehmen die Bereitstellung riesiger Rechenressourcen, ermöglicht aber dennoch den Zugriff auf leistungsfähige KI-Lösungen, die mit dem zunehmenden Erkenntnishunger mitwachsen.
Fakt ist: Jedes Unternehmen muss bei der Entscheidung zum Einstieg in die Welt der KI dafür sorgen, dass konsequent und nachhaltig finanzielle Mittel, Zeit und Ressourcen zur Verfügung stehen, um diese Reise zum Erfolg zu führen. Rückschläge müssen einkalkuliert werden; es darf aber auch mit Erkenntnissen gerechnet werden, die zu erfragen zuvor niemand in der Lage gewesen wäre.
epicinsights ist Ihr kompetenter Berater für alle Themen rund um Künstliche Intelligenz. Mit einem umfassenden Tech-Stack und unserer eigenen Big Data-Infrastruktur realisieren wir für Sie maßgeschneiderte Data-Lösungen und unterstützen Sie auch beim Aufbau datenzentrierter inhouse Teams und Anwendungen.
Immer mehr Unternehmen erkennen die Wirkung, die Data Science auf ihre Wettbewerbsfähigkeit hat. Ein eigenes inhouse Data Team macht Data Science zu einem essenziellen Bestandteil der Unternehmensstrategie. Nach 5 Jahren am Markt sehen wir starke Trends zum Insourcing und plädieren absolut dafür. Data Science ist ein Inhouse-Thema!
Data Science und Machine Learning Teams müssen jedoch sehr gut in die Unternehmensstruktur und -kultur integriert werden, damit sie positive Wirkungen entfalten können. Die Gründung eines Data-Teams (oder einer „Data Unit“) und das richtige Stuffing sind an sich bereits große Herausforderungen – aber nur der erste Schritt.
Hier geben wir einen Überblick über verschiedene Integrationsmöglichkeiten einer Data Unit ins Unternehmen.
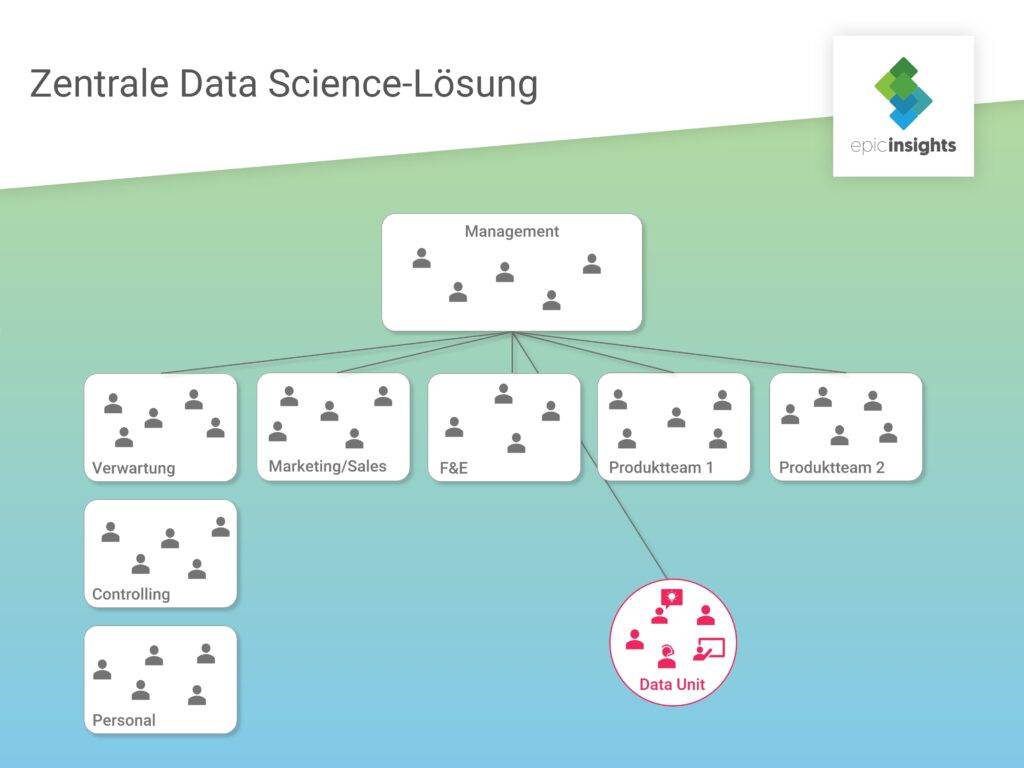
Dezentralisiert arbeiten die einzelnen Datenexperten direkt in den verschiedenen Unternehmensabteilungen. Dazu kommt es vor allem dann, wenn sich die Nachfrage nach Data Science Expertise organisch entwickelt und über die Jahre hinweg vergrößert. Die Abteilungen bemerken ihren Bedarf an Datenanalyse und stellen entsprechendes Fachpersonal ein.
Ein Vorteil dieser Lösungen ist, dass die Data Scientists durch ihre Verankerung in einer Abteilung sehr nah am Tagesgeschehen und damit sensibler für die zu lösenden Probleme sind. Sollte es doch Rückfragen geben, ist zudem eine direkte und schnelle Abstimmung mit den Auftraggebern möglich.
Doch diese Modelle haben auch einige Nachteile. Die Zersplitterung der Data Scientists macht eine Standardisierung der Prozesse und Methoden fast unmöglich. Die einzelnen Datenwissenschaftler kommen zumeist nicht miteinander in Berührung. Das erschwert den Data Science-spezifischen Wissensaustausch und verhindert Synergieeffekte. Darunter leidet am Ende auch die Wettbewerbsfähigkeit, wenn wichtige Zusammenhänge und Verschränkungen unerkannt bleiben. Höhere Kosten für Tools und Infrastruktur sowie ein Effizienzverlust sind die Folgen.
Dezentrale Data Science-Lösungen eignen sich am besten für Unternehmen, die weniger Priorität auf data–driven setzen. Doch auch Unternehmen, die erst am Anfang der Integration von Data Science stehen, profitieren von diesen Lösungen. Auf dem Weg zur eigenen inhouse Data Unit sind dezentrale Lösungen zunächst kosten- und ressourcensparender.
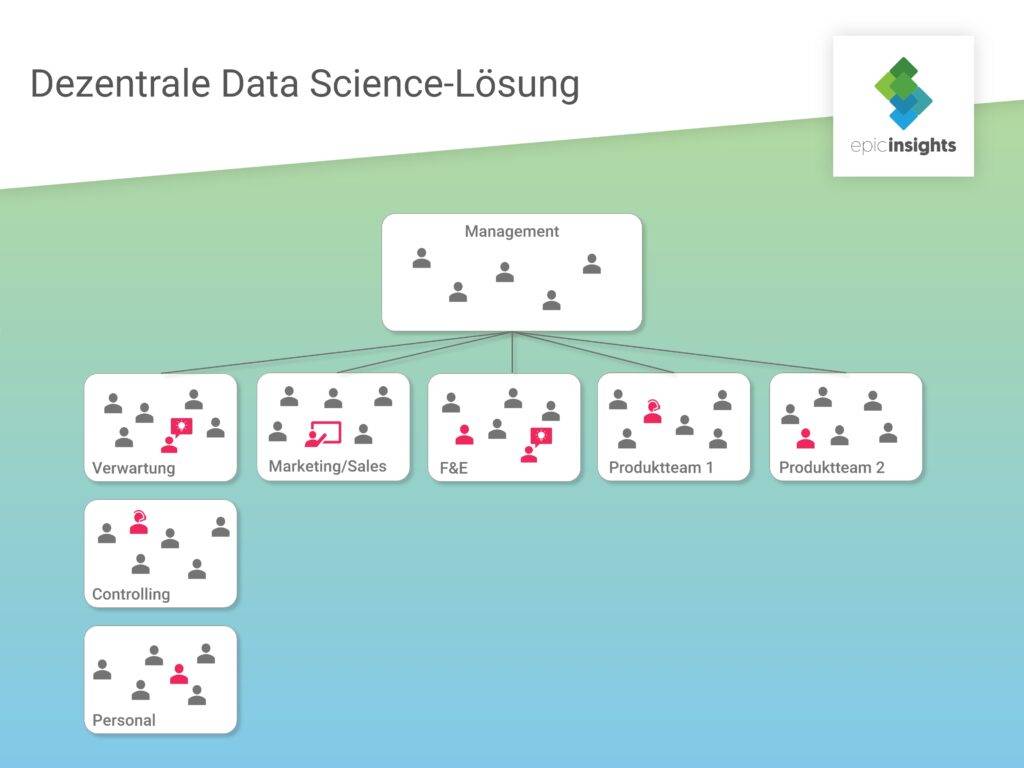
Ein Beispiel für eine dezentralisierte Data Science Lösung ist das Embedded Model. Hierbei teilt sich das Data Science Team nach Bedarf auf unterschiedliche Abteilungen auf, je nach dem, wer ihre Arbeit gerade braucht. Die einzelnen Datenwissenschaftler berichten trotzdem an einen zentralen Head of Data Science. Sie können eine einheitliche Prozess- und Tech-Umgebung aufbauen und nutzen.
Vorteil dieses Modells ist bspw., dass in den einzelnen Abteilungen Datenexperten als Teil eines multidisziplinären Teams vor Ort sind und die Problemstellungen mit den Fachbereichen gemeinsam lösen. Zudem vereinfacht dieses Modell vor allem für kleinere Unternehmen den Managementaufwand, der bei einem zentralen Data Science Team anfallen würde.
Durch die ständige Zuweisung in verschiedene Abteilungen kann sich jedoch nur schwer ein Zugehörigkeitsgefühl aufbauen und der eigentliche Teamgedanke und der so wichtige und notwendige Austausch innerhalb des Data Teams geht verloren. Wegen der Dezentralisierung und Arbeit in den einzelnen Abteilungen werden Optimierungen außerdem nur lokal vorgenommen. Die Gefahr von Insellösungen und Silo-Anwendungen ist hoch. Einen langfristigen Mehrwert für das Unternehmen liefern jedoch eher globale Strategien und ganzheitlich gedachte Optimierungsprojekte.
Auch dieses Modell eignet sich eher für Unternehmen, die bei data driven Strategien am Anfang stehen. Es kann für als Vorstufe – quasi „Experimentierphase“ betrachtet werden, um Data Science langfristig als Kernelement zu verankern. Abteilungen werden schnell handlungsfähig, Mehrwerte können direkt evaluiert werden und das hilft dabei, die Unternehmenskultur auf „data driven“ ganzheitlich vorzubereiten.
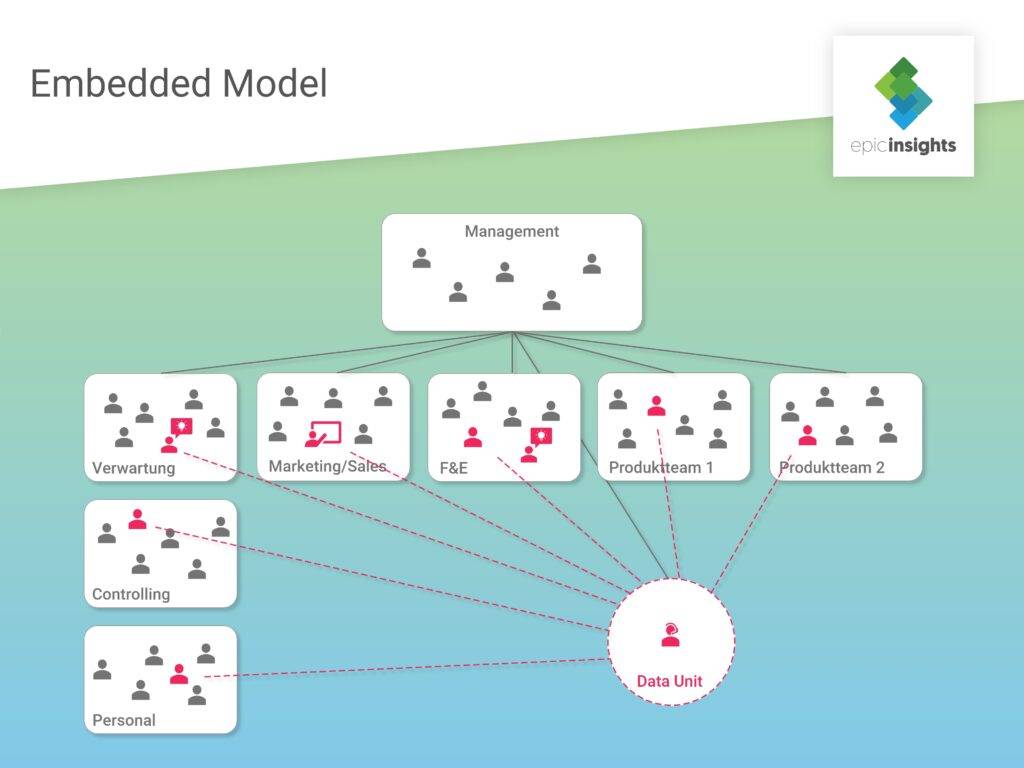
Hierbei ist ein Team an Data Scientists für alle im Unternehmen anfallenden Data Science Fragestellungen zuständig. So kommen sie mit den verschiedensten Projekten und Anforderungen in Berührung.
Vorteilhaft ist bei diesem Modell vor allem die Wissensbündelung an einem Ort. Durch den direkten Austausch der Datenwissenschaftler unter einander lässt sich die Fachkompetenz schneller ausbauen und Spezialisierungen vereinfachen. Zumeist ist auch der Teamleiter ein Experte in Sachen Data Science und damit in der Lage, die anfallenden Aufgaben effizient zu verteilen.
Ein sich daraus ergebender Nachteil ist jedoch die Isolationsgefahr des Data Teams vom Rest des Unternehmens. Die Datenwissenschaftler sind nicht direkt im Tagesgeschäft involviert und verlieren möglicherweise den Blick für das große Ganze. Zudem wird die Kommunikation mit anderen Abteilungen erschwert. Es dauert eine Weile, um Team und Infrastruktur lauffähig zu haben. Dafür muss sichergestellt werden, dass zwar ein notweniger Austausch mit Fachabteilungen stattfindet, aber operative Aufgaben des Tagesgeschäfts nicht die übergeordneten Ziele des Data Teams kannibalisieren.
Eine zentralisierte Data Unit eignet sich vor allem für große Unternehmen. Die diversen und riesig anfallenden Datenmengen (Stichwort: Big Data) erfordern stetig wachsende Analysen und dementsprechend auch ausgebildete Analysten. Der Mehrwert des zentralen Teams kann vor allem durch die Verbindung der Datentöpfe und die Betrachtung aus einer ganzheitlichen Perspektive geliefert werden. Wichtig bei dieser Lösung ist jedoch vor allem, die Analyse Funktion der Unit nicht zu einer Support Funktion für andere Abteilungen werden zu lassen.
Ebenso zentralisiert ist das Data Science Team beim Center of Excellence Model (CoE) als eigene Abteilung angelegt. Die Erwartung hierbei ist, dass die Unit unabhängig vom Rest des Unternehmens arbeitet, um ungestört forschen zu können. Daher wird das Data Science Team auch als Innovationsschmiede des Unternehmens betrachtet. Ein dabei häufig auftretendes Problem ist, die Data Unit zu sehr vom Unternehmensalltag abzuschirmen. Die Datenwissenschaftler sind dadurch weder mit Infrastruktur noch Geschäftsmodell des Unternehmens vertraut und können so auch keine passenden Lösungen liefern.
Andererseits können sich durch die starke Zentralisierung dieses Modells die Data Science Teammitglieder vollkommen auf ihre Arbeit fokussieren und innovative Ideen entwickeln; was unter anderen Umständen nicht so einfach möglich ist. Das Center of Excellence Model ist zudem auf verschiedene andere Arten von Abteilungen oder Teams anwendbar. Für große Unternehmen ist bspw. ein eigenes KI Center of Excellence denkbar.
Wie bereits angemerkt, kann bei diesem Modell das fehlende Wissen über die Unternehmensprozesse ein Problem darstellen. Darüber hinaus ist es für KMU sehr kostenintensiv, ein solches Expertenteam von Grund auf aufzubauen; hier eignen sich vermutlich andere (dezentrale) Lösungen besser.
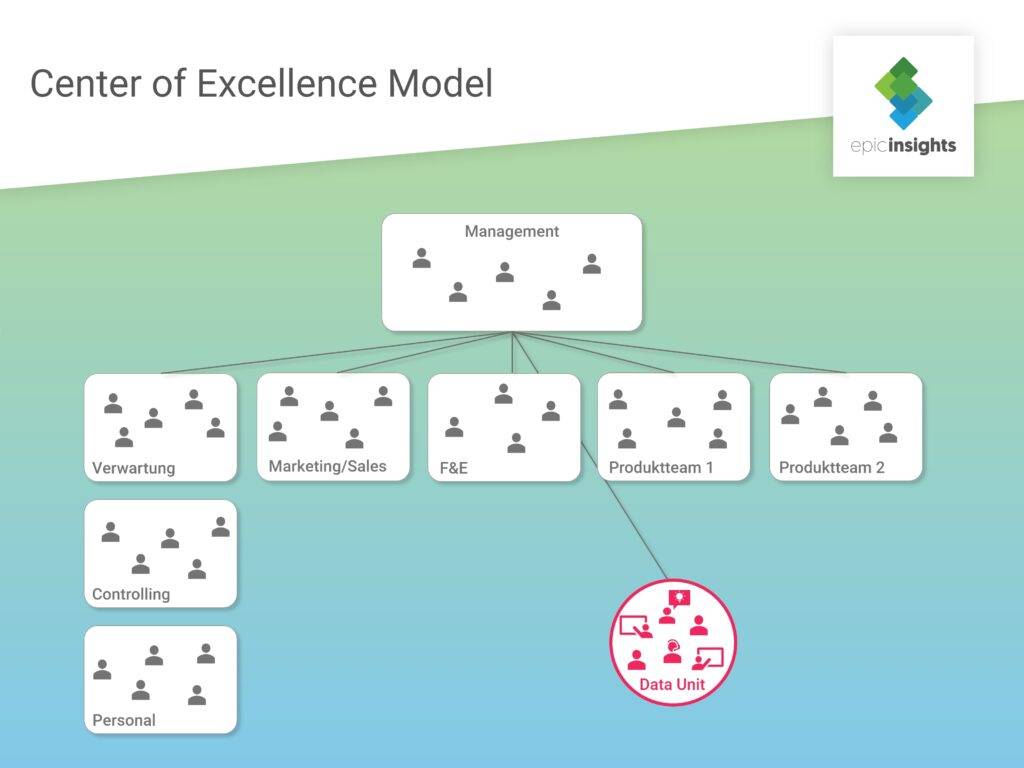
Erfahrungsgemäß erfolgt die Integration von Data Science in Unternehmen oftmals nach dem gleichen Ablauf. Zunächst kommen dezentrale Lösungen zum Einsatz. Wie bereits angemerkt, erfolgt diese Art der Integration durch die organisch steigende Nachfrage nach Data Science in den einzelnen Abteilungen. Ist dieser erste Schritt gemacht, schafft das Embedded Model eine Vorstufe zur alleinstehenden Data Unit. Die einzelnen Datenwissenschaftler sind zwar noch auf die Abteilungen verteilt, berichten aber an einen zentralen Head of Data Science. Ab hier ist es nicht mehr weit zur vollständigen Zentralisierung und eine eigenständige Data Unit nur der logische nächste Schritt.
Neben den dezentralen und zentralen Modellen für die Integration eines Data Science Teams im Unternehmen gibt es auch Modelle, die sich keiner der beiden Arten eindeutig zuordnen lassen. Diese entstanden aus der Praxis heraus; die Unzulänglichkeiten der starren Modelle sollten ausgemerzt und ihre Vorteile wiederum gebündelt werden.
Dieses Modell lässt jeden im Unternehmen zum Datenwissenschaftler werden; zumindest in der Theorie. Durch Business Intelligence Tools und übersichtliche Dashboards hat jeder Mitarbeiter die Möglichkeit, Unternehmensdaten in seine Arbeit mit einzubeziehen. Das Modell ist außerdem mit verschiedenen anderen kombinierbar, bspw. auch mit dem Center of Excellence Model.
Das entlastet die Datenwissenschaftler in ihrer Arbeit. Dadurch können sie sich auf größere Problemstellungen oder Optimierungen konzentrieren. Zudem ist die Investition in Infrastruktur und entsprechende Tools langfristig sehr lohnenswert. Angestellte werden in die Arbeit mit Daten einbezogen und entdecken den Mehrwert, der daraus entsteht.
Natürlich ist die Integration solcher Systeme nicht nur kosten-, sondern auch aufwandsintensiv, was sich nicht jedes Unternehmen leisten kann. Fraglich ist auch, ob die Anwendungen später im Tagesgeschäft überhaupt genutzt werden. Darüber hinaus sind diese Dashboards noch lange keine Datenwissenschaft, dafür sind sie viel zu unterkomplex. Wer also wirklich data driven werden will, braucht ein entsprechendes Expertenteam an seiner Seite.
Wie wäre es mit epicinsights? Wir sind langjähriger Berater für große und kleine Unternehmen rund die Themen Data Science und Künstliche Intelligenz. Wir realisieren wir für Sie maßgeschneiderte Data-Lösungen, Prozesse und unterstützen Sie auch beim Aufbau datenzentrierter inhouse Teams und Anwendungen.