Das Internet der Dinge (Internet of Things, IoT) wird unsere Zukunft maßgeblich verändern. Damit das gelingt, braucht es jedoch eine weitere zukunftsweisende Technologie: Künstliche Intelligenz.
Das Internet der Dinge und Künstliche Intelligenz bilden die Zukunft der digitalen Welt; beide müssen dafür Hand in Hand gehen. Diese Kooperation wird durch die Verbindung von Künstlicher Intelligenz (engl. AI) und IoT als Artificial Intelligence of Things, kurz AIoT bezeichnet. Erst der Einsatz von KI macht Dinge wirklich intelligent. IoT-Geräte führen Datenanalysen in Echtzeit durch. Daraus entsteht ein nie versiegender, kontinuierlicher Datenstrom.
Genau dort liegt die bisherige Schwachstelle vieler KI-Projekte. Auch wenn die Datenmenge auf den ersten Blick ausreichend erscheint, sind die nimmersatten Algorithmen am Ende doch unterversorgt. Das, was nach Cleaning, Transformation und Modellierung übrig bleibt, um ein sehr spezifisches Problem zu lösen, ist oftmals nur ein Bruchteil des Ursprungsdatensatzes. Die intelligenten Maschinen und Geräte stellen durch ihre Vielzahl an Sensoren hingegen immer wieder neue Echtzeitdaten zur Verfügung.
Im Umkehrschluss profitiert IoT ebenfalls von KI; denn die Künstliche Intelligenz macht auch sogenannte Post-Event-Analysen der Datensätze möglich. Mittels Deep bzw. Machine Learning lassen sich innerhalb der gesammelten historischen Daten wiederkehrende Muster erkennen und analysieren. Das ermöglicht bspw. dem Staubsaugeroboter zuhause, aus seinen Einsätzen zu lernen und irgendwann gezielt in bestimmte Räume fahren zu können.
Zudem macht KI IoT sicherer. Durch das kontinuierliche Monitoring und die Mustererkennung lassen sich normale Aktivitäten schnell und zuverlässig von Angriffen auf die Systeme unterscheiden.
Eine IDC-Studie mit Befragten des weltweiten Top-Managements ergab bspw., dass AIoT die Wettbewerbsfähigkeit der Unternehmen im zweistelligen Prozentbereich erhöhte. Als Indikatoren dafür zählten Mitarbeiterproduktivität, Innovationskraft und operative Kosten. Zudem konnten Nutzer von AIoT-Lösungen bspw. auch ihre operativen Vorgänge um 53% beschleunigen.
Wie groß das Potenzial von AIoT für die Qualitätssicherung ist, wird in einem großen deutschen Unternehmen für Elektrotechnik deutlich. Eine automatische optische Inspektion senkte hier die Dauer der Qualitätstests um 45%; das ersparte dem Unternehmen Kosten von 1,3 Millionen Euro. AIoT senkte zudem die Rate nicht erkannter Defekte auf 0% und die Anzahl falscher Alarme auf unter 0,5%.
Ganz anders setzt eine Modekette AIoT im täglichen Geschäft ein. TORY, ein eigens entwickelter Serviceroboter, fährt seit seiner Pilotphase 2015 bereits durch viele Geschäfte. Nach Ladenschluss bewegt er sich selbstständig durch die Läden und scannt die RFID-Tags (Radiofrequenz-Identifikation) der Waren für die Bestandsaufnahme. Dabei erfasst er die genaue Anzahl und Position der Produkte, um Fehlbeständen und Lieferengpässen vorzubeugen. TORY übernimmt damit auch die Stichtagsinventur, die zuvor durch einen externen Dienstleister durchgeführt wurde.
Die folgende Grafik soll vereinfacht darstellen, wie AIoT im Alltag eingesetzt und genutzt werden kann:

Auf der linken Seite ist die physische Welt abgebildet, in der sich alle (A)IoT-Geräte und -Maschinen befinden. Die Menge der dort gesammelten Daten wird kontinuierlich in die digitale Welt übermittelt.
Zunächst muss dieses riesige Datenrauschen bereinigt und die essenziellen bzw. geschäftskritischen Daten herausgezogen werden. Daraus entsteht Wissen darüber, was vor wenigen Minuten an den Geräten passiert ist. Eine Produktionsmaschine könnte bspw. über einen zukünftigen Mangel informieren und Reparaturdienste anfordern. TORY meldet zum Beispiel, dass eine Herrenjacke in einer bestimmten Farbe oder Größe nicht mehr im Laden vorhanden ist.
Mit diesen Informationen lassen sich Entscheidungen treffen und zukünftige Ereignisse vorhersagen. Die daraus abgeleiteten Handlungen beeinflussen rückwirkend wieder die physische Welt. So entsteht ein zuverlässiger Kreislauf aus Datenerfassung und -analyse.
epicinsights ist Ihr kompetenter Berater für alle Themen rund um Künstliche Intelligenz. Mit einem umfassenden Tech-Stack und unserer eigenen Big Data-Infrastruktur realisieren wir für Sie maßgeschneiderte Data-Lösungen und unterstützen Sie auch beim Aufbau datenzentrierter inhouse Teams und Anwendungen.
Dieses Jahr hat es in sich, nicht nur für die Event- und Messeszene, aber vor allem die! Wie jedes Jahr hat man feste Must-Go Termine. Rise of AI ist einer davon. Seit 2016 besuche ich das Event, durfte selbst schon auf der Bühne stehen. Stets bin ich über die spannenden Menschen erfreut, die das Event konzentriert und die ich bisher über die Jahre kennenlernen durfte!
Dieses Jahr ist alles anders. Alles neu. die Pandemie, so anstrengend sie ist, ist auch disruptiv und schafft Dinge, die vorher nur wenig attraktiv oder „einfach“ wirkten. Aber was muss, das muss. So haben Veronika, Fabian und ihr Team das Event dieses Jahr auf 99% digital umgekrempelt – mit viel Aufwand und Leidenschaft. Und das mit Erfolg!
Zeit für ein kleines Recap:
2 Tage voller spannender Vorträge, daran hat man sich ja eigentlich schon gewöhnt bei der Rise of AI. 😉 Also, was gabs Neues? Zusammengefasst kann man festhalten: Das Thema KI wird „erwachsener“. Statt sich trauen, heißt es nun immer stärker, sich den Flaum abstreifen, die Ärmel hochkrempeln und anpacken. Auf Blessuren einstellen, diese wegstecken lernen, das Ziel ins Auge fassen und noch einen Gang höher schalten, bitte! (Quasi das Gegenteil von dem, was im Falle Streetscooter bei der Post passierte)
In vielen Keynotes ging es nicht weniger als um die Wege, wie KI den PoC Status in Unternehmen verlassen und „erwachsen“ werden kann. Der Schlüssel dabei: Business Impact & Scalability. Und das von Beginn an!
Darin verbergen sich keine kleinen Wünsche, darin steckt echte Arbeit und viel Komplexität auf Infrastruktur, Prozess, HR und organisatorischer Ebene. Experimentieren ok, aber bitte mit Weitsicht und es muss was bringen – fürs Business. Es ist schön, dass diese Erkenntnis die Event-Bühnen erreicht hat! Und bei einem weiteren Punkt sind sich alle Keynotes einig: AI ist disruptiv, nicht nur technologisch, sondern auch im Sinne eines zwingenden Change Prozesses, der einmal quer durch die Organisation laufen muss, bis hin zur Unternehmenskultur und dem Mindset von Management und Co. KI ist keine reine Spielwiese (mehr), kein Add-on oder „Modul“, es verlangt aber ein Spielwiesen-Mindset im C-Level, bei Politik und bei allen Förderern. Ebenso wie Risikobereitschaft. Und Durchhaltevermögen! Denn die Chancen überragen die Risiken bei weitem und für „German Angst“ darf gerade kein Platz sein. Stattdessen mehr Neugier, mehr Experimentierfreude, weniger Bürokratie, weniger Vorsicht…mehr Zuversicht! Dieser Narrativ schwebt leider nicht erst seit diesem Jahr über den KI-Bühnen des Landes…
Es tut sich was in Germany, das sieht man an einer großen Portion neuer KI Initiativen und Cluster, die entstehen. Wie z.B. die von Merantix, KI Park Deutschland und KI Berlin. Dabei eine persönliche Bitte: Keine geographischen Silos bauen! Regionale Cluster sind wichtig und gut. Und sie entstehen bzw. wachsen mit großen Erfolg. Aber es muss eine übergreifende Strategie her, die alle Spots aktiv verbindet. Denn KI-Expertise ist in Deutschland verteilt und fragmentiert auf verschiedenste Business Bereiche und Regionen. Der alleinige Fokus auf lokale, virtuelle Hotspots reicht nicht. (auch die Berlin-Power allein reicht nicht… sorry guys 😛 ). Besonders nicht, wenn man in den Dimensionen „Europa“ und „Global“ denken will. Eine große Aufgabe, das zu bewerkstelligen, aber meiner Meinung nach ein wichtiger Schritt in die gemeinsame Zukunft!
Noch ein paar Gedanken zum Thema Remote Event. Zugegeben, ich hatte einige Vorbehalte gegenüber digitalen Events. Habe die meisten gemieden. Ich bin auch absolut kein Fan von: „Lass Konzept A auf Paradigma B portieren – wird schon genauso gut klappen!“. Z.B. beim Thema Messen schön zu beobachten. Oder vor 10 Jahren, als PR nun Social Media machen musste. Das Copy & Paste von bewährten Konzepten in neue Welten hat noch nie wirklich gut geklappt!
Es war mein erstes Digital-Event, bei dem ich 2 Tage von Anfang bis Ende dabei war. Naja fast. Ich mag Live-Events, networking, drinking, talking. Nette Leute treffen, in real und Person! Dieses Jahr gab es das leider nicht. Ich fand es schwer zu fokussieren, wenn man zuhause oder im Büro mehrere Stunden am Stück streamed. Zu viel Ablenkung. Vor Ort hat man keine Wahl, da gibt es die volle Injektion. Feinster Eskapismus. Das ist gut und wichtig. Quasi wie ein 48h Dauer-Energieschub, den man wieder mit nach Hause ins besinnliche Saaletal nehmen und dort fürs Business weiter verdauen kann. Das hat man natürlich remote nicht in der Ausprägung. Dafür kann man die Sessions aber nach und nach über mehrere Tage häppchenweise konsumieren. Sich etwas Zeit blocken, wo man Ruhe finden kann. Das war gut und führt zu einem weiteren Vorteil: Man kann alle Sessions sehen, während man in live wegen überschneidender Slots und Networking eben einige verpasst und es deutlich stressiger ist.
Das Networking und der Realtalk gehen verloren, das ist die (leider sehr weittragende) Downside des Modus. Aber das ist nicht ROAI-spezifisch, nicht Event-spezifisch. Das betrifft gerade den allgemeinen (Zwischen-)Zeitgeist, der hoffentlich 2021 wieder endet.
Das schöne an diesem Event war, dass es nicht allzu starke Placement-Vorträge gab, viel Quality Input. Sehr gut getaktet und wie immer gut moderiert, gern mehr davon!
So, well: Nach 4 Jahren ROAI, Hut ab an Fabian und Veronika für ihr nimmermüdes Engagement! Freude auf ROAI’21, stay safe!
Cheers, Michi
Das Internet der Dinge (engl. Internet of Things, IoT) stellt die Verbindung zwischen realer und digitaler Welt her. Seit Jahren wächst diese Technologie kontinuierlich und auch für die Zukunft werden goldene Zeiten und fast grenzenlose Möglichkeiten für das Internet der Dinge prognostiziert. Welche Vorteile IoT für Ihr Unternehmen bietet und welche Rolle Künstliche Intelligenz dabei spielt, erfahren Sie im Folgenden.
Die Bezeichnung ist eigentlich selbsterklärend: Verschiedenste Gegenstände werden mit dem Internet vernetzt und sind dadurch in der Lage, selbstständig miteinander zu kommunizieren und Aufgaben zu erfüllen. In Abgrenzung zu dieser Definition wird das klassische Internet als Social Internet bezeichnet, weil hier Menschen untereinander bzw. mit Maschinen kommunizieren. Im Internet der Dinge lassen sich Geräte hingegen nicht allein von Benutzern steuern, sondern kommunizieren durch Machine-to-Machine-Communication direkt miteinander und können Aufgaben so auch komplett automatisiert erfüllen.
Die Anwendungsbereiche von IoT sind vielfältig. Sie ermöglichen Innovationen wie Smart City, -Industry, -Health und natürlich Smart Home; alles wird intelligent! Connected Cars, die untereinander kommunizieren und auf Gefahren oder nahende Verkehrsprobleme aufmerksam machen oder Industrieanlagen, die drohende Mängel vorhersagen und selbstständig das passende Ersatzteil bestellen und den Techniker rufen, sind nur zwei Beispiele.
Für private Haushalte bedeutet IoT zum Beispiel, dass ein intelligenter Kühlschrank in Zukunft selbstständig „merkt“, wann sich bestimmte Lebensmittel dem Ende neigen und bestellt diese unter Umständen vollkommen autonom nach. Und das alles ist erst der Anfang; das Internet der Dinge wird unser gesamtes Leben künftig maßgeblich verändern und eine Menge Komfort und automatisierte Prozesse schaffen. Die Einsatzmöglichkeiten sind dabei nahezu unendlich.
Auch die Arbeitswelt wird sich durch das Internet der Dinge stark wandeln. In der Industriebranche spricht man abweichend nicht vom IoT, sondern von IIoT, dem Industrial Internet of Things. Im Deutschen hat sich stellvertretend dazu seit längerem der Begriff Industrie 4.0 etabliert. Wie im Privathaushalt sind auch hier die einzelnen Geräte untereinander vernetzt, nur handelt es sich dabei nicht um Toaster oder Staubsauger, sondern oftmals um riesige Produktionsmaschinen und -anlagen. Ziel dieser Vernetzung ist eine Produktion zu garantieren, in der sowohl die Maschinen als auch die Menschen effizient miteinander kommunizieren und kooperieren. Das optimiert die gesamte Wertschöpfungskette und reduziert gleichzeitig Kosten.
Besonders in der Produktion erweist sich IIoT als nützlich. Die Maschinen liefern kontinuierlich und meist in Echtzeit eine Vielzahl verschiedener Daten. Diese Datenbasis ermöglicht nicht nur einen genaueren, sondern auch einen aktuelleren Blick auf das eigene Unternehmen und die zugrundeliegenden Prozesse. Durch diese prädiktiven Informationen lassen sich bspw. Wartungskosten und Neuinvestitionen zuverlässig planen.
Die übermittelten Daten werden allgemein als Maschinendaten bezeichnet. Diese lassen sich nach einfachen Datenpunkten und komplexen Datensätzen unterscheiden. Erstere werden kontinuierlich bzw. bei möglichen Veränderungen aufgezeichnet und sind daher Prozessdaten. Sie werden mit dem entsprechenden aktuellen Wert und einem Zeitstempel abgespeichert. Damit lässt sich der Zustand der Maschinen über die historischen Datenreihen hinweg analysieren. Die komplexen Daten werden als zusammenhängende Datensätze aufgezeichnet. Neben dem Zeitstempel enthalten sie zusätzlich genaue Informationen zu den Datenobjekten, welche die Daten geliefert haben (bspw. Produktionsaufträge, Maschinennummern etc.). Die im Datensatz enthaltenen Daten sind daher abhängig vom jeweiligen Anwendungsfall; es handelt sich also zum Beispiel um Prüfergebnisse oder Verbrauchsdaten.
Ein entscheidender Vorteil der Prozessdaten ist ihre Rolle bei der Optimierung der Maschineninstandhaltung. Hier ergeben sich zwei Möglichkeiten:
Die Digitalisierung stellt für so manche KMU eine Hürde dar. Auch die Implementierung von IoT-Produkten kann zum Problem werden. So sind beispielsweise in der Produktion nicht alle Maschinen auf dem neusten technischen Stand und die Anschaffungs- bzw. Anpassungskosten sehr hoch. Um jedoch automatisiert Maschinendaten erfassen zu können, ist eine durchgängige Vernetzung Grundvoraussetzung. Maschinen benötigen für die zumeist IP-basierte Vernetzung entsprechende Netzwerkkomponenten. In modernen Maschinen sind diese bereits fertig verbaut und müssen nur noch aktiviert und konfiguriert werden.
Darüber hinaus sind die Technologien für das Internet der Dinge viel fragmentierter als im „Internet der Menschen“, was die Kommunikation der Geräte untereinander angeht. Die dafür notwendigen einheitlichen und unabhängigen Standards und Kommunikationsprotokolle sind bisher noch nicht hinreichend etabliert.
Eine Studie von Kaspersky zeigt, dass mittlerweile auch die Sicherheit von IIoT-Systemen in Gefahr ist. 28% der Befragten gaben an, 2019 bereits Sicherheitsprobleme mit IoT-Plattformen gehabt zu haben. Vor dem Einsatz von IoT sollten Unternehmen diese Sicherheitsfragen also genau evaluieren und präventiv in entsprechende Schutzsysteme investieren. Auf dem Spiel stehen Datenschutz, die Sicherheit der Systeme und Anlagen sowie der allgemeine Arbeitsschutz.
Daneben ändert sich durch die Industrie 4.0 auch die organisatorischen Ebenen vieler Unternehmen. IoT und die Digitalisierung lassen neue Geschäftsmodelle entstehen. Um auf dem Weg ins digitale Zeitalter nicht auf der Strecke zu bleiben, braucht es mutige und kreative Visionäre, die bereit sind, diesen neuen Weg zu beschreiten. Daneben ist auch qualifiziertes Personal mit hoher IT-Affinität und Datenkompetenz notwendig, um diesen Weg zu ebnen.
Nicht nur die Produktion wird von IoT/IIoT profitieren. In der Logistikbranche ist der Einsatz von IoT-Systemen bereits weit verbreitet. So werden unter anderem die Fahrzeugrouten durch GPS-Tracking erfasst und sowohl Kunden als auch Unternehmen können den aktuellen Ort ihrer Ware gezielt nachverfolgen.
Auch für autonomes Fahren wird das Internet der Dinge essenziell werden, damit die Fahrzeuge untereinander sicher vernetzt sind und kommunizieren können. Für die besonders wichtige Übermittlung von Echtzeitdaten braucht es zudem den 5G Mobilfunkstandard.
Für das Marketing und den Vertrieb werden besonders die neuen verfügbaren Datenmengen von großem Nutzen sein. Detaillierte Informationen zu Produkten, der Produktnutzung und dem Kaufverhalten liefern ganz neue Einblicke in das Tagesgeschäft. Dadurch ist es zukünftig noch besser möglich, auf die individuellen Bedürfnisse der Kunden einzugehen und ihre Customer Journey bestmöglich zu personalisieren.
epicinsights ist Ihr kompetenter Berater für alle Themen rund um Künstliche Intelligenz. Mit einem umfassenden Tech-Stack und unserer eigenen Big Data-Infrastruktur realisieren wir für Sie maßgeschneiderte Data-Lösungen und unterstützen Sie auch beim Aufbau datenzentrierter inhouse Teams und Anwendungen.
Wir freuen uns sehr, ein Partnerunternehmen des diesjährigen Makeathons der Lichtwerkstatt Jena sein zu dürfen. Dieser findet im Rahmen der Photonics Days 2020 am 21. und 22. September statt. Dieses Jahr ist das gesamte vom Fraunhofer IOF und der Max Planck School of Photonics organisierte Netzwerkevent komplett online, bedeutet: Jeder kann von überall aus mitmachen!
Der Makeathon startet am 21. September 10 Uhr und endet 22 Uhr. Die Aufgabe wird darin bestehen, originelle hard- und softwarebasierte Lösungen für eine reale Problemstellung zum Thema Optik und Photonik zu entwickeln.
Klingt interessant? Dann schnell sein: Die Anmeldefrist wurde auf den 18. September bis 12 Uhr verlängert. Hier geht’s zur Registrierung. Wir freuen uns auf euch und eure Ideen!
Die Photonics Days bieten eine gute Möglichkeit für Studierende und Promovierende sich mit Vertretern innovativer Unternehmen der Optik- und Photonikbranche zu vernetzen. Das Programm hält dabei vielfältige Möglichkeiten für spannenden Input bereit: Neben verschiedenen Keynotes und Pitches können sich Teilnehmende auf der digitalen Karriere-Messe am 22. September von Vertretern renommierter Unternehmen hinsichtlich Beruf und Bewerbung beraten lassen. Um bei all diesen Informationen einen kühlen Kopf zu bewahren und alles zu verarbeiten, sind natürlich auch Mittags- und Kaffeepausen im Programm eingeplant.
Zunächst ein Throwback: Während des 2. Weltkriegs untersuchten die Engländer vom Einsatz zurückkehrende Flugzeuge auf ihre Schäden und Einschüsse. Ziel war es, die Panzerung der Flugzeuge daraufhin an den Stellen zu verstärken, wo besonders viele Einschüsse verzeichnet wurden.
Der Mathematiker Abraham Wald stellte jedoch damals klar, dass dieses Vorgehen einem Trugschluss unterliegt. Es wurden dabei nämlich nur die rückkehrenden Flugzeuge geprüft; also die, die den Einsatz überstanden hatten. Um die Rückkehrquote der Flieger zu verbessern, müssten jedoch die untersucht werden, die nicht zurückkehrten, also die abgestürzten Flugzeuge. Natürlich war das nicht möglich. Daher legte er nahe, vielmehr die Stellen zu verstärken, die nicht getroffen wurden; denn die beschädigten Bereiche der zurückgekehrten Flugzeuge hinderten die Maschinen augenscheinlich nicht am Fliegen.
Es geht also beim Survivorship Bias darum (oder besser bei der Vermeidung dieser kognitiven Verzerrung), nicht dem Trugschluss zu erliegen, dass das vermeintlich naheliegendste zweifelsfrei als das „richtige“ angenommen wird. Es geht darum, nicht direkt sichtbare Ereignisse einzubeziehen und sich darüber bewusst zu werden, dass Erfolge überbetont wahrgenommen werden. In den scheinbaren Niederlagen liegen jedoch möglicherweise viel mehr Informationen, die es zu hinterfragen gilt. Es geht um einen bewussten Perspektivwechsel.

Der Sachverhalt lässt sich tatsächlich sehr gut auf das Analysieren der eigenen Zielgruppe im Online Business, prototypisch im E-Commerce, übertragen. Auch hier ist das Ziel klar: Mehr Kunden gewinnen, mehr Verkäufe generieren, mehr User zur Rückkehr bewegen.
Ich schaue mir im CRM an, wie die Kunden aussehen, die ich schon gewonnen habe. Denn über sie habe ich viele Informationen. Ich kenne ihre Käufe, ihr Geschlecht, ihren Wohnort, ihr Nutzerverhalten und einige Metadaten.
Darauf aufbauend entwickle ich dann Personas, meine Kundenprofile, die ich wiederum als Basis für das Targeting verwende. Logisch: Ich analysiere, wer meine Kunden sind und suche nach Personen, die als potenzielle Neukunden in Frage kommen. Ich baue mir also über die passenden Eigenschaften entsprechende Schablonen und versuche neue Nutzer zu finden, die in diese Schablone passen. Über Targeting-Möglichkeiten wie Lookalike Audience kann ich diese sogar durch einige ihrer Eigenschaften gezielt „vermehren“ und mit Hilfe anderer Plattformen nach ähnlichen Nutzern Ausschau halten.
Im „klassischen“ Vorgehen ist die Gefahr also sehr hoch, dass ich dem Survivorship Bias unterliege; zumindest, wenn ich nicht konkret auf Bestandskundenentwicklung fokussiert bin, sondern Neukunden gewinnen möchte.
Denn: Nur diejenigen zu betrachten, die kaufen, sagt mir noch lange nicht, wie ich solche konvertiere, die nicht kaufen.
Die (zu) einfache Antwort: Hört auf, Nutzer in Schablonen bzw. Schubladen zu pressen! Dieser antiquierte Ansatz ist weder dynamisch, noch hat er irgendetwas mit der Realität eurer Nutzer zu tun. Schablonen haben nur einen einzigen Sinn: Sie machen die komplexe Welt einfach, verständlich, handhabbar. Andererseits steht diese fälschlicherweise verkleinerte Welt fernab der Realität, die leider sehr komplex und chaotisch ist. Menschen lassen sich in ihrem Verhalten nicht in Schablonen pressen. Ein Kunde, der heute ein bestimmtes Verhaltensprofil hat, kann morgen oder übermorgen ein ganz anderes haben, mit anderen Zielen, Intentionen und Bedürfnissen. Das „klassische“, starre Segmentierungsvorgehen bildet diese Dynamik nicht ab. Kurz gesagt lasse ich als Unternehmer viel Potenzial ungenutzt.
Um mir ein umfängliches Bild über meine Nutzer zu verschaffen, darf ich mir nicht ausschließlich die Käufer anschauen, sondern muss ALLE Nutzer mit im Blick haben. Und um besser zu verstehen, wie ich Nutzer konvertiere, muss ich mir die anschauen, die nicht konvertieren. Ich muss vor allem die Dynamik des Nutzerverhaltens in die Analyse mit einbeziehen. Mir muss klar sein, dass sich Kundenbedürfnisse quasi mit jedem Besuch oder sogar während eines Besuches ändern können. Und darauf muss ich in irgendeiner Form reagieren können.
Der Einbezug von Metadaten und damit der zeitlichen Perspektive ist besonders wichtig. Diese geben Aufschlüsse über den aktuellen Nutzungskontext während des Seitenbesuchs und bei der Kaufentscheidung.
Als Lösung für die o.g. Probleme haben wir sogenannte Fluide Personas entwickelt. Sie sind unser Weg, mittels Künstlicher Intelligenz objektiv und datengetrieben das Verhalten aller Nutzer zu analysieren und auch die Signale der Nicht-Kunden miteinzubeziehen. Sie zeigen dabei bspw. nicht nur, welche Seiten gern aufgerufen werden, welches technische Setup (bspw. Browser oder Betriebssystem) die User nutzen und welcher Content, wann konsumiert wird. Fluide Personas geben auch einen direkten Überblick, wie diese Eigenschaften miteinander zusammenhängen hinsichtlich der Entscheidung zum Kauf – oder eben zum Nicht-Kauf.
Darüber hinaus berücksichtigen Fluide Personas das dynamische Verhalten der Nutzer, indem Sie wechselnde Verhaltensweisen in die Analyse einbeziehen. Dieses Wissen darum, was den Nutzern objektiv wirklich wichtig ist, nutzen wir dann, um für unsere Kunden eigene prädiktive Algorithmen zu entwickeln, um z.B. Content zu personalisieren oder Strategien für die Content Kreation und dessen Distribution über verschiedene Kanäle abzuleiten.
Die wenigsten Agenturen und Unternehmen besitzen die richtigen Prozesse, Ressourcen und Technologien für explorative, datengetriebene Nutzersegmentierungen.
Wir ändern das.Eine Google-Suche reicht aus, um auf schier endlose Jobbezeichnungen im Data Science Bereich a.k.a. Data Roles zu stoßen. Bei näherer Betrachtung wird deutlich: Es gibt weder einheitliche Definitionen dieser Tätigkeitsfelder noch lassen sie sich konkret voneinander abgrenzen. Um das zu verdeutlichen, stellen wir im Folgenden einige vor.
Für einen Datenmehrwert im Unternehmen braucht es sowohl die entsprechenden Data Skills als auch die jeweiligen Verantwortlichen für verschiedenste datenbezogene Aufgabenstellungen. Das Verknüpfen unterschiedlicher Infrastrukturkomponenten sowie die Bereinigung und Analyse der bestehenden Datenmengen wird erst durch das Zusammenspiel der verschiedenen Data Roles möglich.
Die Dynamik des Arbeitsmarkts, vor allem im Bereich Künstlicher Intelligenz, sorgt jedoch dafür, dass scheinbar täglich neue Jobs und Jobbezeichnungen aus dem Boden sprießen und eine trennscharfe Abgrenzung dieser gar nicht mehr so leichtfällt. Eine Methode, sich in diesem Dschungel zurechtzufinden, ist den Fokus mehr auf die Data Skills der einzelnen Akteure zu legen. Was wir damit meinen, sehen Sie hier:
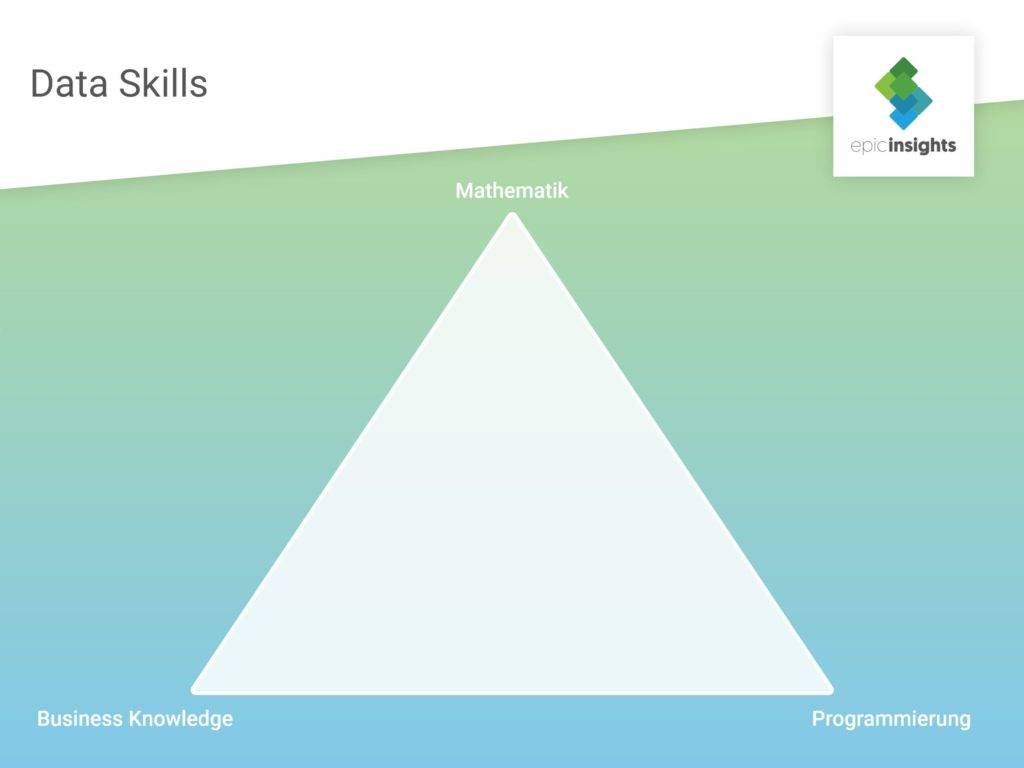
In dieser Grafik lassen sich alle Data Roles entsprechend ihrer erforderlichen Skill Sets verorten. Um zu zeigen, wie nah einige dieser Data Roles beieinander liegen, folgen nun einige Beispiele:
Der Dateningenieur oder auch ETL-Ingenieur (Extrahieren, Transformieren, Laden) ist in den Unternehmensdatenbanken und Verarbeitungssystemen zuhause. Hier kümmert er sich um die Dateninfrastruktur, baut Datenpipelines und stellt die komprimierten Daten für die weitere Verwertung zur Verfügung.
Wenn Sie einen tiefergehenden Einblick in die Arbeit des Data Engineers erhalten wollen, dann klicken Sie hier.
Machine Learning Operations (kurz MLOps) sorgen für reibungslose Abläufe innerhalb des ML-Entwicklungsprozesses. ML-Operator stellen sicher, dass alle benötigten Tools zur Verfügung stehen, die Infrastruktur und Umgebungen zugänglich sind. Damit sorgen sie auch für die reibungslose Zusammenarbeit und Kommunikation zwischen Datenwissenschaftlern und IT-Spezialisten bei der Umsetzung und Automatisierung von ML-Algorithmen.
ML-Operator stellen sicher, dass der ML-Lebenszyklus effizient, gut dokumentiert und mögliche Probleme einfach zu beheben sind. Die Anforderungen, die sie an Machine Learning stellen sind Reproduzierbarkeit, Kollaboration, Skalierbarkeit und Kontinuität. Ihre Arbeit ist dadurch mit Development Operations (DevOps) vergleichbar, jedoch konkret auf die Anforderungen von Machine Learning zugeschnitten.
Neben Big Data ist Data Science wohl DAS Buzzword der letzten Jahre. Doch viele Unternehmen und Entscheider überschätzen die Kernaufgaben eines Data Scientists wahrscheinlich noch. Natürlich kann diese Stelle mit einem wahren Allrounder besetzt werden, aber das sagenumwobene Data Unicorn gibt es (leider?) trotzdem nicht.
Zum Aufgabenbereich des Data Scientists gehören bspw. die Auswahl der passenden Methoden, die Entwicklung von Vorhersagemodellen oder auch die Optimierung von Neuronalen Netzen. Mit Hilfe dieser lassen sich zukünftige Ereignisse vorhersagen und dementsprechend Entscheidungen treffen. Data Scientists sorgen also dafür, den größtmöglichen Nutzen aus den verfügbaren Unternehmensdaten zu ziehen.
Auf einem umkämpften Bewerbermarkt sind Datenwissenschaftler ein begehrtes Gut. Effektive Data Scientists sind geübt im Zusammenspiel mit Backend- und Frontend-Entwicklern, kennen agile Arbeitsmethoden und aktualisieren stetig ihren Methodenkoffer.
Der Data Analyst leistet vergleichbare Arbeit wie der Data Scientist. Er behält die Unternehmensdaten stets im Blick, um schnellstmöglich Auffälligkeiten darin zu identifizieren und darauf reagieren zu können. Zudem bereinigt der Data Analyst die Daten, analysiert sie (obviously), führt Testläufe durch und leitet seine Ergebnisse an andere Unternehmensstellen weiter.
Die genaue Unterscheidung von Data Analyst und Data Scientist ist gar nicht so leicht. Ein Unterschied zwischen den beiden Data Jobformen ist aber bspw., dass der Datenanalyst geschäftskritische Fragestellungen von anderen Abteilungen (z.B. Marketing) entgegennimmt und nach einer Lösung dafür sucht. Der Data Scientist hingegen formuliert Fragestellungen an einen Datensatz in der Regel selbst.
Der Statistiker sorgt mit Fachwissen aus der Mathematik für eine andere Perspektive auf die Daten. Dadurch kann er bspw. bestimmen, welche Methode der Datenerfassung sich für einen bestimmten Zweck am besten eignet. Mit seiner logischen Denkweise sammelt er die Daten, wandelt sie in Informationen um und liefert daraus nützliche Erkenntnisse. Zudem liegt ihm auch die Entwicklung analytischer Modelle und mathematischer Algorithmen.
Die besondere Datenkompetenz des Statistikers sorgt vor allem dafür, voreilige Schlüsse über die Daten bzw. den Datensatz zu verhindern. Nur weil bspw. eine Machine Learning Methode in einem Data Set funktioniert hat, lässt sich dies nicht automatisch auch auf andere übertragen. Statistiker helfen so Entscheidern, über die analysierten Daten hinaus zu sinnvollen Schlussfolgerungen zu kommen.
Die Rolle des Business Analysts unterscheidet sich wohl am meisten von den hier bisher aufgeführten. Im Gegensatz zu den anderen Data Roles hat er weniger tiefgreifendes Technikwissen, dafür aber umso mehr Verständnis für die verschiedenen Unternehmensprozesse.
Der Business Analyst verwandelt die gefundenen Data Insights in umsetzbare Business Strategien, um das Unternehmen weiter voranzubringen. Das macht ihn zum Sprachrohr zwischen Data Unit und Entscheidungsträgern. Als Industrie-Insider erkennt er zudem die wichtigsten Trends und hält die kosteneffektivsten Lösungen für das Unternehmen bereit.
Kommen wir also zurück zur vorgestellten Grafik und schauen uns an, wo sich die einzelnen Data Roles dort verorten lassen:
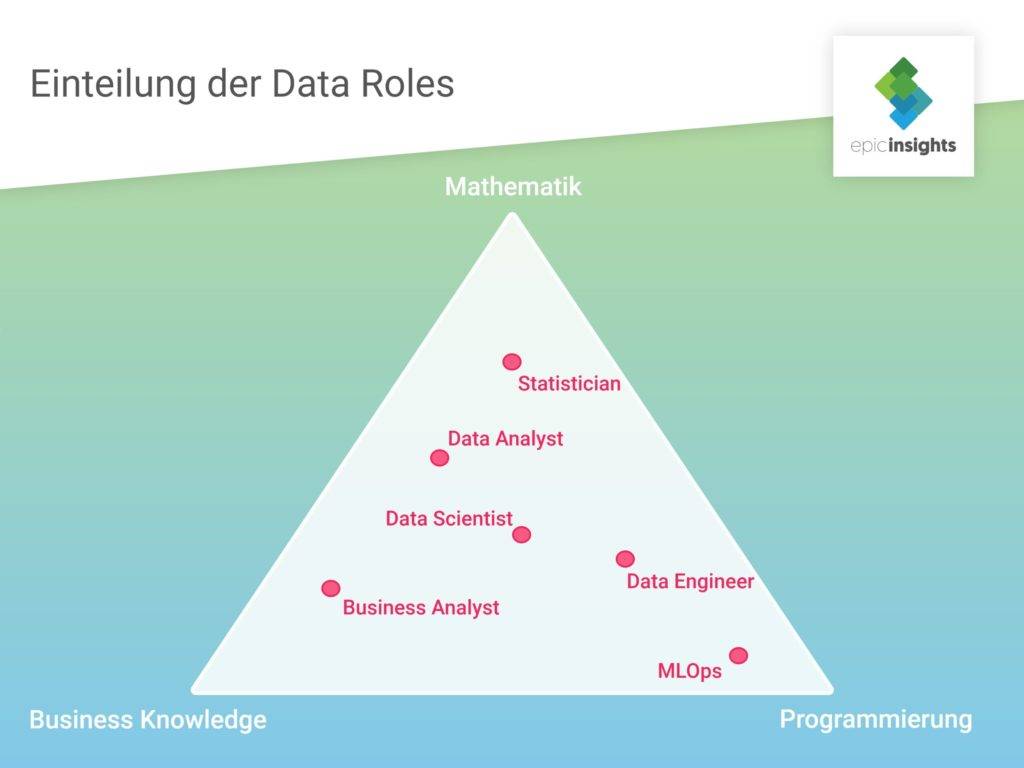
Hier wird ersichtlich, wie nah die einzelnen Rollen in ihren Skill Sets beieinander liegen. Bereits bei der Beschreibung wurde deutlich, dass sich bspw. die Aufgabenbereiche von Data Scientist und Data Analyst stark ähneln. In der Grafik wird diese Similarität noch einmal mehr als deutlich.
Bei der Zusammensetzung des Data Science Teams spielen vor allem die Unternehmensgröße und die umzusetzenden Ziele eine entscheidende Rolle. Sicher ist es bspw. für ein kleineres Unternehmen mit überschaubaren Ressourcen nicht sinnvoll (und vor allem nicht nötig), eine Vielzahl an Data Roles besetzen zu wollen.
Vielmehr sollte anfangs darauf geachtet werden, eher weniger Personal, dafür aber mit einem breiten Kompetenzspektrum, einzustellen; also mit breiteren Data Skills. Wächst das Unternehmen und damit auch Budget und Anforderungen an das Data Team, kann der Fokus auf einen größeren Ausbau der einzelnen Data Roles gelegt und eine stärkere Spezialisierung der einzelnen Mitglieder angestrebt werden.
Für viele Unternehmen stellt sich weiterhin die Frage, ob ein zentrales oder dezentrales Data Science Team sinnvoller ist. Die zentrale Lösung steht für die Bündelung der einzelnen Team Mitglieder an einem Ort, ein sogenanntes Data Science Competence Center. Dezentral hingegen sind einzelne Data Scientists o. ä. in den verschiedenen Fachabteilungen eingesetzt. Auch hier müssen vor allem die Unternehmensgröße und die individuelle Data-Strategie des Unternehmens beachtet werden.
Möchten Sie auch ein eigenes Data Science Team aufbauen oder sind vielleicht sogar schon dabei? Egal, was Sie vorhaben:
epicinsights hilft Ihnen mit hochspezialisierten Consultants und vielen Jahren Projekt-Erfahrung. Mit einem umfassenden Tech-Stack und unserer eigenen Big Data-Infrastruktur realisieren wir für Sie maßgeschneiderte Data-Lösung und unterstützen Sie auch beim Aufbau datenzentrierter inhouse Teams und Anwendungen.
Für eine erfolgreiche Datennutzung im Unternehmen braucht es entsprechend kundiges Personal. Viele denken dabei vermutlich sofort an Data Scientists, da diese für eine saubere Auswertung der Daten essenziell sind. Doch nur die Zusammenarbeit mit einer anderen Teamrolle führt letztendlich zum Erfolg. Die Rede ist von Data Engineers.
Der Data Engineer bildet quasi das erste Glied in der Data Science-Kette. Sein Arbeitsgebiet sind die Unternehmens-Datenbanken. Da die hier liegenden Daten meist in verschiedenen Formaten gespeichert sind, besteht die Hauptaufgabe des Daten Ingenieurs darin, diese zugänglich und für spätere Analysen auswertbar zu machen. Dafür baut er Datenpipelines und -plattformen, mit deren Hilfe die Daten zusammengeführt und systematisiert werden. Er stellt so die Grundlage für die Arbeit der Data Scientists her.
Die konkreten Aufgabenbereiche von Data Engineers variieren je nach Unternehmensgröße. So lassen sich bspw. diese drei Formen von Data Engineering unterscheiden:
Grundlegend stellen Data Engineers also strukturierte Daten für die weitere Arbeit der Data Scientists zur Verfügung. Der Fokus des Data Engineers liegt auf der passenden Kombination der Software-, Hardware- und Datenbank-Architekturen des Unternehmens. Wichtige Themengebiete sind hierbei die Datensicherheit bzw. der Datenschutz, die Datenqualität und die IT-Sicherheit. Sie sorgen für die Verfügbarkeit und Verwertbarkeit der Daten innerhalb der nachfolgenden Unternehmensprozesse.
Data Engineers und Data Scientists stehen daher in enger Zusammenarbeit, teilweise überschneiden sich ihre Aufgaben auch. Die Arbeit der Data Engineers ist vom eigentlichen Ergebnis der Analysen und dem Projektbericht in der Wertschöpfung sicher weiter entfernt. Doch sie sind es, die für die erfolgreiche Vernetzung zwischen den verfügbaren Rohdaten und allen Abteilungen, die für ihre Arbeit auf diese Daten angewiesen sind, sorgen. Erst durch Data Engineers werden Use Cases ermöglicht wie die Aufnahme und Speicherung großer Datenmengen (also Big Data) und die Automatisierung der Machine Learning Modelle und Algorithmen.
Die voranschreitende Digitalisierung stellt viele Unternehmen vor eine Herausforderung. Deshalb ist es wichtig, möglichst frühzeitig das große Potenzial von Data Engineers zu erkennen – besonders, wenn man im Bereich KI und Data Science noch am Anfang steht – und eine entsprechende Rolle im Team vorzustehen. Für die immer komplexer werdenden IT-Infrastrukturen, Datenanalysen und das Datenmanagement sind Entscheider auf (daten-)kompetentes Personal angewiesen.
Haben Sie das Potenzial von Data Engineering erkannt? Egal wie groß Ihr Unternehmen ist: We enable AI for your business.
epicinsights hilft Ihnen mit hochspezialisierten Consultants und vielen Jahren Projekt-Erfahrung. Mit einem umfassenden Tech-Stack und unserer eigenen Big Data-Infrastruktur realisieren wir für Sie maßgeschneiderte Data-Lösung und unterstützen Sie auch beim Aufbau datenzentrierter inhouse Teams und Anwendungen.
Auch wenn Ihnen Künstliche Intelligenz (alias KI oder AI) bereits etwas sagt; bevor wir mit der Liste der gängigsten Data Mining Methoden starten, stellt sich dann vielleicht doch noch eine andere, entscheidende Frage:
Bei Data Mining handelt es sich um die Erforschung, Analyse und Auswertung großer Datenmengen. Auf der Suche nach versteckten Mustern und Strukturen werden vor allem Big Data-Bestände „geschürft“. Mit den gewonnenen Datenerkenntnissen lassen sich Unternehmensentscheidungen automatisieren, präzise Prognosen und Vorhersagen treffen und langfristig Kosten senken. Mit Data Mining ist es möglich, die versteckten Geschichten im Datenchaos einer Marke zu lokalisieren. Die Entwicklung intelligenter Softwarelösungen steht und fällt mit dem Erschließen solcher Dark Data.

Bei der Clusteranalyse wird die zumeist riesige Datenmenge in kleinere Gruppen (Cluster) eingeteilt. Dafür werden Ähnlichkeiten innerhalb der Daten analysiert und auf Grundlage dieser die Gruppen gebildet. Für eine genaue Abgrenzung der Gruppen untereinander müssen die Unterschiede zwischen ihnen möglichst groß sein.
Die Einsatzbereiche von Clusteranalysen sind vielfältig. Eine typische Marketinganwendung ist zum Beispiel die Segmentierung nach Zielgruppen. So werden Personen mit übereinstimmenden Eigenschaften entsprechenden Clustern zugeordnet, um im Folgenden die passenden Produkte oder Angebote an sie auszuspielen.
Die Klassifizierung oder Klassifikation ist eine der beliebtesten Data Mining Methoden in der Praxis. Im Unterschied zur Clusteranalyse sind die Gruppen, in diesem Fall die Klassen, denen die Daten auf Grund ihrer Eigenschaften zugeordnet werden, bereits vordefiniert. Die Zuordnung der sogenannten Trainingsdaten zu diesen Klassen erfolgt durch bestimmte Entscheidungsregeln. Die wesentlichen Klassifikationsverfahren sind Entscheidungsbäume, Künstliche Neuronale Netze, die Bayes-Klassifikation und das k-Nächster-Nachbar-Verfahren. Eine davon möchte ich kurz vorstellen:
Wie die Bezeichnung bereits suggeriert, ist dieses analytische Modell der Arbeitsweise des menschlichen Gehirns nachempfunden. Erstaunlich ist, dass das Verfahren bereits in den 1940ern entwickelt wurde, jedoch erst in den letzten Jahren große Beliebtheit erlangte. Wie beim Original handelt es sich auch hier um ein Netz unabhängiger, in Schichten (sog. Layers) aufgebauter Neuronen. Diese Schichten sind untereinander verbunden. Zumeist besteht das Netz nur aus einer Ein- und Ausgabeschicht. Manche Künstliche Neuronale Netzwerke weisen dazwischen jedoch noch weitere Schichten auf. Eine Besonderheit der KNN ist ihre Lernfähigkeit mittels Trainingsdaten.
Die Regressionsanalyse trifft Vorhersagen mit Hilfe erkannter Beziehungen innerhalb des Datensatzes. Sie deckt den Zusammenhang zwischen einer abhängigen und einer oder mehrer unabhängigen Variablen auf. Die verfügbaren Daten prognostizieren so zukünftiges Verhalten. Es gibt grundlegend zwei Arten von Regression:
Die Assoziationsanalyse dient der Identifikation von Elementen, die häufig miteinander auftreten, also im Zusammenhang stehen. Die dafür benötigten Assoziations- bzw. Abhängigkeitsregeln resultieren aus den erkannten Häufigkeiten innerhalb der Datenmenge.
Ein einfaches Beispiel für diese Data Mining Methode ist die Warenkorbanalyse. So untersuchen bspw. Lebensmittelgeschäfte, welche Produkte häufig zusammen im Warenkorb der Kunden landen. Als Resultat könnten sie ihre Märkte so aufbauen, dass Produkte, die meist zusammen gekauft werden, möglichst weit von einander entfernt angeboten werden. Auf der Suche nach dem gewünschten Produkt müssten die Kunden erst an einer Vielzahl anderer vorbei, was ihren Warenkorb mehr füllen könnte als ursprünglich geplant.
Der Name ist Programm: Die Anomalieerkennung identifiziert in einem Datensatz von der Norm abweichende Muster und unvorhergesehenes Verhalten, sogenannte Outliers. Die Methode kommt bspw. bei der frühzeitigen Erkennung von Fraud-Aktivitäten zum Einsatz. Allgemein gibt es drei Anomalie-Kategorien:
Die Charakterisierung verschiedener Anomalien ist wichtig, um für ihre Erkennung den passenden Algorithmus zu wählen.
Die Weiterentwicklung von Geschäftsprozessen basiert zunehmend auf datengetriebenen Entscheidungen. Die Wettbewerbsfähigkeit steht und fällt also mit der korrekten Applikation von Data Mining. Der Schlüssel dazu ist ein funktionales Data Science-Team. Sie kennen ihren Werkzeugkasten und die richtigen Kniffe. Doch Data Scientists allein reichen nicht aus. Eine weitere Baustelle ist die Datenbeschaffung aus verschiedenen Quellen.
epicinsights hilft Ihnen mit hochspezialisierten Consultants und vielen Jahren Projekt-Erfahrung. Mit einem umfassenden Tech-Stack und unserer eigenen Big Data-Infrastruktur realisieren wir für Sie maßgeschneiderte Data-Lösung und unterstützen Sie auch beim Aufbau datenzentrierter inhouse Teams und Anwendungen.

Data Literacy, zu dt. Datenkompetenz, bezeichnet die Fähigkeit, auf kritische Art und Weise versiert mit Daten umzugehen und diese kontextuell bewusst einzusetzen. Sie unterteilt sich in verschiedene Einzelkompetenzen wie Datenerfassung, -analyse oder -visualisierung. Besonders der Bereich Big Data erfordert eine neue Form der Alphabetisierung.
Für unsere heutige, digital-durchdrungene Gesellschaft ist die Datenkompetenz der einzelnen Mitglieder essenziell. Nur so kann die Digitalisierung umfassend vorangetrieben werden. Im Zuge dessen wird sich auch die Arbeitswelt verändern; sie wird zunehmend datengetrieben. Somit wird Data Literacy zukünftig zur Grundkenntnis, die Arbeitnehmer brauchen, um nicht auf der Strecke zu bleiben. Immer mehr Unternehmen erkennen, wie kostbar Daten für ihren wirtschaftlichen Erfolg sind und welcher Wettbewerbsvorteil der richtigen Nutzung von Zero Party Data oder Big Data-Technologien innewohnt. Daher ist es für sie von großer Wichtigkeit, dass auch ihre Mitarbeiter, durch alle Abteilungen hindurch, den Wert von geschäftskritischen Daten erkennen und in der Lage sind, deren Informationsgehalt zielführend und kompetent für ihre Arbeit zu nutzen.
Doch auch außerhalb des Jobs ist der kritische Umgang mit Daten und Informationen im Allgemeinen zu einer wichtigen Fähigkeit geworden. In Zeiten einer alles umfassenden Digitalisierung, Fake News und Smart Devices gilt es, neue Technologien und Informationen mit einem gesunden Maß an Skepsis einzuordnen und nicht allen Heilsversprechen blind zu vertrauen.
Ein amüsantes Beispiel, wie sogar reale Daten im falschen Kontext täuschen können, zeigt die Website tylervigen.com. Hier finden sich die absurdesten (Nicht-)Korrelationen, dargestellt in professionell anmutenden Diagrammen. Auf Grundlage dessen könnte bspw. angenommen werden, dass es einen Zusammenhang zwischen der Zahl an Menschen, die in einem Pool ertranken und Filmen, in denen Nicolas Cage mitspielte, gäbe. Das lassen wir jetzt einfach mal so stehen. 😉
Besonders jetzt, in der unsicheren Lage der Corona Krise, wollen sich Menschen auf die vermeintlich sicheren Daten verlassen, die täglich aktualisiert und neu veröffentlicht werden. Doch warum das nicht so einfach geht, erklärt Katharina Schüller auf dem Blog des Hochschulforums Digitalisierung. So können die berechneten Modelle zur Verbreitung und Sterblichkeitsrate des Virus nur vage Aussagen über die Wirklichkeit treffen. Die vorhandenen Daten seien für eine zuverlässigere Berechnung unzureichend und nicht repräsentativ. Vor allem aber die exponentielle Ausbreitung des Virus mache eine Prognose schwer.
Ein Beispiel für die mögliche Fehlinterpretation der Daten birgt die Betrachtung von Neuinfektionen mit Covid-19. Diese mit den verhängten Ausgangsbeschränkungen allein zu korrelieren, sei falsch, meint Schüller. So lässt sich die gesteigerte Infektionsrate u.a. auf ein neuartiges Testverfahren zurückführen, das schnellere und damit mehr Tests von Verdachtsfällen ermöglicht.
Ein kritischer Blick auf diese Zahlen ist also wichtig, um nicht in Panik zu verfallen, aber den Ernst der Lage auch nicht zu unterschätzen. Erst in den nächsten Wochen wird sich wirklich zeigen, wie erfolgreich die getroffenen Maßnahmen zur Eindämmung des Virus sind.
Ein erster Schritt nachhaltiger Datenkompetenz innerhalb der Gesellschaft ist das entsprechende Lehr- bzw. Lernangebot, beginnend in der Schule. Um bei der Digitalisierung nicht abgehängt zu werden, müssen die Datenexperten von morgen bereits heute an das Thema herangeführt werden. Durch passende Angebote in den Schulen bzw. die direkte Integration von Data Science Aspekten in die einzelnen Fächer, würden Schüler von Anfang an für den Umgang mit Daten sensibilisiert werden. Diese Kenntnisse wären ein wichtiger Grundstein für ihren weiteren (digitalen) Werdegang.
Um dieses Ziel zu erreichen, muss jedoch noch einen Schritt weiter gedacht werden. Schüler können Datenkompetenz nur von datenkompetentem Lehrpersonal erlernen. Dafür muss es auch an Hochschulen entsprechende Studienangebote geben. Doch nicht nur angehenden Lehrern müssen die einzelnen Komponenten von Data Literacy vermittelt werden. Vielmehr müssen die entsprechenden Lehrveranstaltungen studienübergreifend sein, um Studierenden aller Fächer den kompetenten Umgang mit Daten zu vermitteln. Nur so erreicht die Digitalisierung zukünftig alle Branchen und Fachbereiche.
Auch Unternehmen müssen zunehmend data driven werden, um wettbewerbsfähig zu bleiben. Natürlich braucht es dazu ausgebildetes Fachpersonal, sprich Data Scientists. Sie wissen, wo sich die wertvollen Daten verstecken, wie sie zu interpretieren und schlussendlich als ultimativer Wettbewerbsvorteil einzusetzen sind. Doch Data Scientists allein reichen nicht aus. Auf allen Ebenen sind deshalb Datenliteraten notwendig, die genau wissen, wie sie die vorhandenen Daten für ihre Arbeit nutzen können. Weiterbildungen und Beratungsangebote sind ein guter Schritt, dieses Ziel zu erreichen.
epicinsights hilft Ihnen, in der Datenflut nicht unterzugehen. Unser Team aus hochspezialisierten Consultants und Data Scientists mit jahrelanger Projekterfahrung unterstützt Sie auf Ihrem Weg zur Digitalisierung. Aus unseren vielfältigen Angeboten entwickeln wir für Sie eine maßgeschneiderte Data-Lösung und helfen Ihnen auch beim Aufbau datenzentrierter inhouse Teams und Anwendungen.
Künstliche Intelligenz (im engl. abgekürzt als AI) ist bereits heute nicht mehr aus unserem Alltag wegzudenken. Privatpersonen kommen bspw. über Sprachassistenten und Produktempfehlungen tagtäglich mit Künstlicher Intelligenz in Berührung. Unternehmen profitieren vor allem bei ihrer Datenanalyse von der Schnelligkeit und Zuverlässigkeit von KI. In beiden Fällen handelt es sich um Narrow AI / Artificial Narrow Intelligence; zu deutsch: schwache KI.
Diese Form Künstlicher Intelligenz ist erst der Anfang. Die nächste Stufe wird als General AI (bzw. Artificial General Intelligence) bezeichnet. Und sogar darauffolgend soll es mit Super AI (bzw. Artificial Super Intelligence) irgendwann eine weitere KI-Evolution geben. Aber beginnen wir in der Gegenwart.
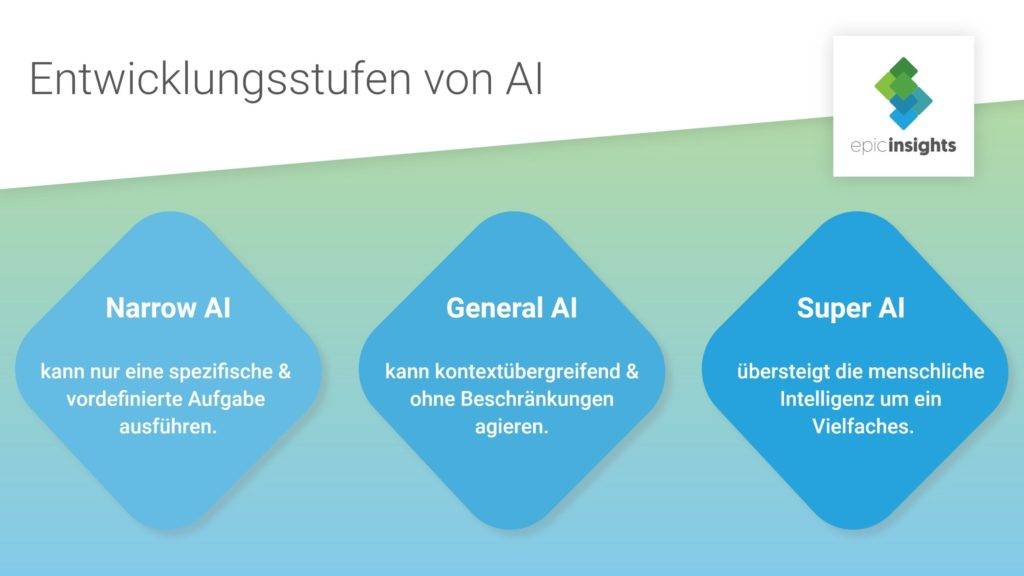
Wir befinden uns aktuell auf der ersten Entwicklungsstufe Künstlicher Intelligenz. Hierbei wird KI in der Regel nur für eine spezifische, vordefinierte Aufgabe genutzt. Das liegt unter anderem daran, dass schwache Künstliche Intelligenzen die benötigten Informationen lediglich aus bestimmten Datensätzen entnehmen und somit an diese gebunden sind. Im Alltag sind viele mit solchen KI-Systemen bereits, bewusst oder unbewusst, in Berührung gekommen. Man findet sie z.B in Sprachassistenz-Systemen oder bei der Online-Bildersuche. Auf ihrem entsprechenden Gebiet agieren die Systeme aber in Echtzeit und übertreffen in ihrer Arbeit bereits häufig menschliche Effizienz.
Im Gegensatz zu schwacher KI kennt General AI keine Beschränkungen. Die Systeme sind imstande, ihr Wissen und ihre Fähigkeiten in den verschiedensten Kontexten anzuwenden. Sie führen jede ihnen gestellte Aufgabe aus und agieren dabei auf demselben Niveau wie ein Mensch, vermutlich sogar weitaus schneller und effizienter. Von General AIs wird erwartet, dass sie argumentieren, unter Unsicherheit urteilen, planen und sogar einfallsreich und kreativ sein können.
Diese Form Künstlicher Intelligenz ist bisher nur Science-Fiction. Bis wir künstliche Assistenten wie „Jarvis“ aus Ironman haben werden oder uns sogar in solche Systeme verlieben, wie im Film Her, dauert es wohl noch. Experten sind sich uneinig, ob und wenn ja, wann General AI Wirklichkeit wird. Die Schätzungen reichen von 2030 bis 2060.
Artificial Super Intelligence ist vorerst die letzte Entwicklungsstufe, die wir uns mit heutigem Wissen vorstellen können. Dank dystopischer Science-Fiction-Filme fürchtet sich vermutlich ein Großteil davor. Super AI übersteigt die menschliche Intelligenz um ein Vielfaches. Kein Wunder, dass es längst unzählige düstere Zukunftsvisionen gibt, in denen Maschinen die Weltherrschaft übernehmen. Wird es wirklich soweit kommen??
Ray Kurzweil, Director of Engineering bei Google, ist sich sicher: „KI wird uns nicht verdrängen, sie wird uns verbessern„. Statt eines erbitterten Machtkampfes, würden Menschen und Maschinen viel mehr co-existieren. Vor allem die Menschheit würde von dieser Symbiose profitieren. Laut Kurzweil soll es uns bis 2045 mit Hilfe einer hybriden KI möglich sein, eine Neocortex-Verbindung zu Cloudsystemen, sogar zu anderen Menschen, herzustellen. Die Daten, auf die wir damit über unser Gehirn zugreifen könnten, wären quasi unendlich. Das würde nicht nur die technische Evolution rasant voranbringen, sondern auch unsere eigene.
Bis jetzt liegen General und Super AI noch in unerreichbarer Ferne. Niemand kann mit Sicherheit sagen, wann wir die erste der beiden Stufen wirklich erreichen werden. Experten gehen jedoch davon aus, dass der nächste Schritt zwischen den beiden KI-Formen vergleichsweise klein ausfallen wird.
In bestimmten Feldern übertrifft KI heute schon die menschliche Leistungsfähigkeit. Insbesondere dann, wenn es um die schnelle Verarbeitung von vielen Informationen in kürzester Zeit und das Erkennen von datenseitigen Mustern geht. Durch unsere Fähigkeiten, wie abstraktes, kreatives Denken, der Entwicklung von Strategien oder der Entscheidungsfindung basierend auf Erfahrungen und Erinnerungen, sind wir KI-Systemen in komplexen Situationen noch weit überlegen. Vor allem dann, wenn es um die Kombination von mehreren Wahrnehmungsebenen und nicht rein logikbasierte Aufgaben geht. Diese komplexen Strukturen künstlich in eine Maschine zu replizieren, stellt aktuell eine unüberwindbare Hürde dar. Auch die Rechenleistung, mit der unser Gehirn Daten verarbeitet, kann zu diesem Zeitpunkt kein Computer der Welt aufbringen.
Ein Beispiel für die Leistungsfähigkeit schwacher KI ist unser hauseigenes KI-Framework epicAi. Integriert in einen Onlineshop erfasst und analysiert die Künstliche Intelligenz Verhaltensdaten und segmentiert vollkommen unbekannte Nutzer binnen Millisekunden anhand ihrer Eigenschaften und Interessen. Mit Hilfe unserer sogenannten Fluiden Personas wird die Veränderlichkeit der unterschiedlichen Nutzersegmente nachvollziehbar. Dadurch werden neue, bisher ungeahnte, Handlungsoptionen sichtbar.