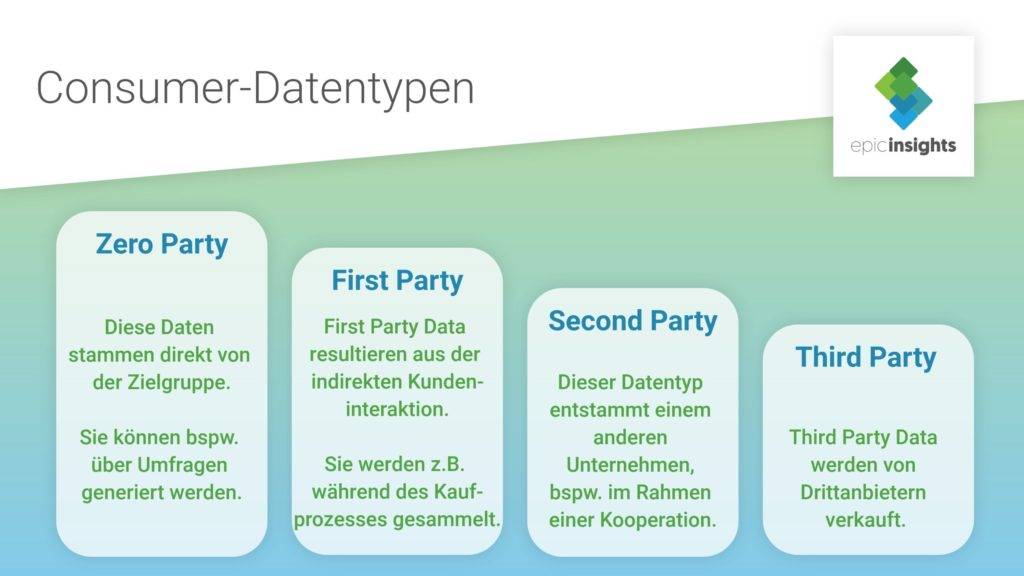
Mit den Zero Party Data erscheint ein neuer Datentyp auf der Marketing-Bildfläche. Aber was hat es damit überhaupt auf sich? Um auf diese Frage eine Antwort zu finden, beginnen wir das Thema Datenanreicherung zunächst etwas allgemeiner:
First Party Data sind Daten, die aus der Interaktion zwischen Unternehmen und Kunden stammen. Sie werden in der Regel während des Kaufprozesses generiert. Dazu zählen beispielsweise Cookies oder Klickpfade. Die auf diese Weise gesammelten Daten unterliegen den Datenschutzrichtlinien des Unternehmens.
Dieser Datentyp ist reich an wertvollen Verhaltensdaten und Informationen über frühere Käufe. Die First Party Data zeigen, wie ein Kunde mit der Marke interagiert oder wie sich sein (Kauf-) Verhalten über die Zeit hinweg verändert. Sie bilden das Fundament für den Aufbau von Kundenstammdaten. Zukünftige Kaufabsichten können über diese historischen Daten jedoch nur erahnt werden. Vorhersagen sind somit implizit und unzuverlässig. Die Erschließung neuer Zielgruppen ist allein mit diesem Datentypen nicht möglich.
Diese Daten stammen aus der Hand eines anderen Unternehmens bspw. im Rahmen einer Kooperation. Meine Second Party Data sind also die First Party Data eines Geschäftspartners. Die Verwendung und Nutzung dieser Daten sind durch die Datenschutzbestimmungen beider Unternehmen limitiert.
Mit den Second Party Data überwinde ich die Beschränkungen der First Party Data. Mit dem verbesserten Datenmix habe ich unter anderem die Möglichkeit, meine Reichweite und die Effektivität von Kampagnen zu steigern. Die Vorhersage von zukünftigem Kaufverhalten ist treffsicherer als beim ersten Datentyp.
Als Third Party Data werden Daten bezeichnet, die von Drittanbietern generiert werden. Meist regelt ein Kaufvertrag ihre Nutzung. Third Party Data umfassen zum Beispiel demografische Informationen von Nutzern und geben weiterhin Rückschlüsse auf deren Interessen und (Kauf-) Absichten. Mit Third Party Data kann ich meine Kundenstammdaten um relevante Informationen ergänzen.
Benötige ich spezielle Datensätze oder eine sehr große Datenmenge, sind Third Party Data hilfreich. Die schnelle Verfügbarkeit und der Umfang vorliegender Daten sind große Vorteile dieses Datentyps. Jedoch steht deren Datenqualität in Verruf, da sie oft aus einer Vielzahl nicht miteinander in Verbindung stehender und unzuverlässiger Quellen stammen. Sie können dadurch auch schnell veralten und meine Datenqualität negativ beeinflussen. Weiterhin kritisch ist der Datenschutzaspekt. Um die personenbezogenen Daten erheben und nutzen zu können, muss der Kunde darüber informiert werden, was mit seinen Daten geschieht und dem einwilligen.
Nun aber zu den Zero Party Data. Diese stellt der Kunde dem Unternehmen bereitwillig und proaktiv zur Verfügung. Marketer sammeln diese Daten, indem sie sich direkt mit den Nutzern in Verbindung setzen und deren Bedürfnisse abfragen.
Statt auf implizite und teilweise ungenaue Kundendaten zu setzen, können Marketer nun konkrete Aussagen und Informationen ihrer Zielgruppe verarbeiten. Das wirkt sich positiv auf die Personalisierung von Dienstleistungen, Angeboten und Produktempfehlungen aus.
In Zeiten von Datenschutzskandalen sind Verbraucher vorsichtiger, wie viele ihrer persönlichen Daten sie preisgeben. Weiterhin sind auch Marketer durch die DSGVO eingeschränkter, was das Sammeln und Auswerten von Verbraucherdaten betrifft. Die Zero Party Data bieten hierbei einen Kompromiss mit Vorteilen für beide Seiten.
Die konkrete Ansprache und Befragung der Kunden ermöglicht Marketern, ungefilterte Daten direkt von der Zielgruppe zu erhalten. Auch die Kundenbindung und das Vertauen in die Marke können sich so verbessern. Die Verbraucher sind aktiv in Marketingentscheidungen eingebunden und können im Umkehrschluss direkter angesprochen werden. Privatsphäre und Personalisierung müssen sich also nicht ausschließen.
Die Zero Party Data sind zudem weitaus aktueller als Drittanbieterdaten und spiegeln mit größerer Wahrscheinlichkeit die genauen Bedürfnisse der Verbraucher wider. Für Marketer bedeutet das die Steigerung ihrer Datenqualität, da sie nicht mehr nur auf implizite und veraltete Informationen setzen müssen. Zudem kommt es mit den zuverlässigen Zero Party Data zur Datenanreicherung.
Natürlich braucht es gewisse Anreize, Kunden persönliche Daten zu entlocken. Hierfür gibt es verschiedene Möglichkeiten.
Unternehmen können bspw. Gewinnspiele durchführen, die mit der Teilnahmebedingung verbunden sind, ein paar persönliche Angaben zu machen. Eine ähnliche Option sind Rabatte im Austausch gegen Daten. Auch kurze Fragebögen mit dem Ziel der Personalisierung von Produktempfehlungen sind sowohl für Kunden als auch Marketer sehr hilfreich.
Gleichwohl können auch die Kunden den ersten Schritt machen und selbst aktiv werden, zum Beispiel über Interaktionen und Beiträge auf Social Media. Diese können Unternehmen zur Orientierung für neue Marketingstrategien dienen. Auch User-Mails mit Fragen oder Kritik bzw. Dialoge mit Chatbots können für diese Zwecke ausgewertet werden.
Der Einsatz der passenden Methode liefert Ihnen möglicherweise ganz neue Informationen über Ihre Zielgruppe, deren Wünsche und Erwartungen an Ihre Marke. Dabei sollte jedoch vor allem Transparenz im Vordergrund stehen. Die Nutzer müssen darüber informiert werden, wofür sie ihre Daten zur Verfügung stellen. Dann bilden Zero Party Data einen erfolgsversprechenden Weg zur Personalisierung im Einklang mit Datenschutzrichtlinien.
Während Ad Fraud in den USA bereits seit Längerem eine omnipräsente Bedrohung in der Digital Marketing Welt ist, thematisieren wir es hierzulande noch vergleichsweise wenig. Doch zunehmend erreicht der kommerzielle Werbebetrug auch Deutschland. Wir geben Ihnen in diesem Artikel einen Überblick über die Arten von Ad Fraud und die passenden Gegenmaßnahmen. Machine Learning stellt hierbei eine verlässliche und vielleicht sogar entscheidende Lösung dar.
Eine klare und vor allem einheitliche Definition des Begriffs Ad Fraud gibt es nicht. Das führt dazu, dass die verschiedenen Anbieter von Ad Verification Systemen Ad Fraud ebenfalls unterschiedlich identifizieren. Im Ergebnis schwanken die von ihnen erhobenen und veröffentlichten Werte teilweise stark.
Die Fokusgruppe Digital Marketing Quality des BVDW führt daher zur zukünftigen Vereinheitlichung den Begriff Invalid Traffic (IVT) ein. Dieser unterteilt sich zum Einen in General Invalid Traffic (GIVT). Hierunter fallen alle Werbekontakte von „gutartigen“ Bots. Diese geben sich als solche zu erkennen und zeigen Online Marketing Systemen an, als nicht abrechnungsrelevant aus den Reportingdaten herausgefiltert werden zu können. Manche Anbieter von Ad Fraud Detection-Lösungen rechnen diese Impressions fälschlicherweise dem Sophisticated Invalid Traffic (SIVT) zu. SIVT-Werbekontakte können einerseits Non-Human, also bspw. von programmierten Bots verursacht werden. Andererseits können sie auch von Menschen stammen, dann jedoch so manipuliert, dass sie keine Werbewirkung erzielen. SIVT erfasst alle Impressions, die mit vermeintlich betrügerischer Absicht manipuliert und erzeugt werden. Aus diesem Grund kann hier von Ad Fraud die Rede sein.
Die Methoden von Online-Betrügern sind vielfältig und ausgeklügelt. Entwickeln Tech-Unternehmen neue Lösungen, sie auffliegen zu lassen, ziehen die Fraudster nur wenig später mit ebenfalls neuen Varianten des Werbebetrugs nach. Fraud Investigation wird so zu einem Wettrennen zwischen Wirtschaftskriminalität und Data Analytics.
Click Fraud bzw. Klickbetrug ist die einfachste und daher häufigste Form des Anzeigenbetrugs. Traffic wird hierbei entweder durch sogenannte Click Bots oder durch Angestellte in einer Click Farm erzeugt. Die Bots sind mittlerweile technisch so ausgefeilt, dass sie menschliches Klickverhalten authentisch nachahmen können. Sie sind beispielsweise darauf programmiert, Mausbewegungen zu imitieren oder unterschiedlich lange Pausen zwischen den Klicks zu lassen. Das macht ihre Identifikation als (non-human) SIVT kompliziert.
Ein Lead-Anbieter stellt die Art und Weise, wie ein Lead generiert wird, falsch dar. Beispielsweise können die Lead-Authentizität, das Lead-Alter oder die Website-Herkunft verfälscht werden. In diesem Fall handelt es sich um Lead Fraud. Diese Faktoren können den Kaufwert eines Leads drastisch verändern. Davon profitiert natürlich der Lead-Verkäufer, wobei der Käufer der Geschädigte ist. Sein Targeting verpufft dann wirkungslos.
Impressionsbetrug bedeutet, dass die geschaltete Werbeanzeige nicht an ihre relevante Zielgruppe ausgeliefert wird, aber die Impressions trotzdem gezählt werden. Für diese Art des Werbebetrugs gibt es verschiedene Möglichkeiten. Eine der bekanntesten Methoden ist Ad-Stacking. Hier werden verschiedene Anzeigen einfach übereinander gestapelt. Ein und derselbe Werbeplatz auf einer Website kann also mehrmals verkauft werden.
Dies ist nur kleiner Auszug von Ad Fraud Methoden. Die Liste könnte zukünftig wahrscheinlich immer wieder erweitert werden. Doch wie kann ich diese immer komplexer werdenden Betrugstaktiken aufdecken und mich dagegen schützen?
Auch auf dieser Seite gibt es verschiedenste Möglichkeiten, wiederum gegen die Betrüger vorzugehen. Im Folgenden möchte ich ein paar davon nennen.
Signaturbasierte Methoden nutzen spezielle Aktivitätsmuster, um verdächtiges Impressions-, Traffic- oder Klickverhalten herauszufiltern. Diese Muster oder Schemata werden mit der erfassten Aktivität verglichen. Darauffolgend muss bestimmt werden, ob es sich um auffällige, also stark vom Muster abweichende, bzw. sogar betrügerische Aktivität handelt und ob weitere Schritte eingeleitet werden müssen.
Diese Methode nutzt statistische Analysen und historische Daten, um Werbeplätze, Websites und Publisher zu überprüfen und Anomalien festzustellen. Dazu zählen beispielsweise verdächtig hoher Traffic oder fragwürdige Werbeflächenplatzierungen.
Methoden basierend auf Berechtigungsnachweisen wägen die Möglichkeit betrügerischer Aktivitäten ab. Es wird Reverse Crawling verwendet, wobei die Berechtigungen der auffällig gewordenen Source überprüft werden, so zum Beispiel Registrierungsdaten, Ranking oder Aktivität. Anschließend wird ein Vergleich mit den Anforderungen für Impressions durchgeführt. Außerdem wird der Wert mit vertrauenswürdigen Rankings verglichen.
Hierbei wird den Werbebetrügern eine Falle gestellt, ein sogenannter Honeypot. Ein zusätzliches Feld wird in das Online-Formular eingefügt, welches jedoch für menschliche Nutzer aufgrund eines speziellen Skripts nicht sichtbar ist. Bots hingegen füllen dieses Feld aus und verraten sich selbst. Die Bot-Aktion löst einen Mechanismus aus, der zukünftige betrügerische Aktivitäten sperrt.
Da sich die Methoden von Werbebetrügern immer rasanter weiterentwickeln, müssen Marketer ebenso schnell mit Gegenmaßnahmen nachziehen. Eine besonders effiziente Lösung stellt Machine Learning dar.
Im Vergleich zu menschlichen Datenanalysten arbeiten Machine Learning Algorithmen deutlich zeitsparender und genauer. Sie können eine große Menge an Daten in Echtzeit analysieren, verarbeiten und die gefundenen Aktionen sofort auswerten. Ad Fraud Aktivitäten werden damit schneller identifiziert als bisher. Fortschrittliche Modelle wie Neuronale Netze aktualisieren sich sogar autonom, um die neusten Trends widerzuspiegeln. Ein weiterer Vorteil von Machine Learning ist, dass sich die Modelle mit zunehmenden Datenmengen verbessern und effektiver arbeiten. Betrügerische Aktionen können damit auch für die Zukunft zuverlässig vorhergesagt und blockiert werden.
Bereits in der Bezeichnung Dark Data schwingt eine gewisse Bedrohlichkeit mit. Doch wie gefährlich sind diese „dunklen Daten“ wirklich? Ich möchte etwas Licht ins Dunkel bringen. Daher zunächst die Frage:
Dark Data ist ein Teilgebiet von Big Data. Zusammengefasst steht der Begriff für die Menge an Daten, die in einem Unternehmen zwar gespeichert werden, jedoch meist ungeschützt, ungenutzt und unstrukturiert auf Servern liegen. Einer Studie zufolge schätzt ein Drittel der befragten Führungskräfte die Menge von Dark Data auf 75% ihrer Gesamtdaten.
Neben Dark Data lassen sich zwei weitere Gruppen von Unternehmensdaten unterscheiden:
Die geschäftskritischen Daten bilden für den Geschäftserfolg die relevanteste Gruppe. Sie werden in Echtzeit gesammelt sowie analysiert und liefern einen unternehmerischen Mehrwert. Die geschäftskritischen Daten stellen nicht den Großteil des Datenvolumens dar. Viel mehr bilden sie einen vergleichsweise geringen Anteil an der Gesamtdatenmenge.
Die dritte Datengruppe sind die ROT-Daten. ROT steht für „Redundant, Obsolet, Trivial“. Diese Daten haben keinen Geschäftswert. Unternehmen sollten sie daher in regelmäßigen Abständen löschen. Beispiele für ROT-Daten sind Spam oder Werbung.
In dieser Kategorisierung haben Dark Data einen besonderen Stellenwert. Da die entsprechenden Daten (noch) ungenutzt bleiben, ist unklar, wie viel Potenzial wirklich in ihnen steckt. So könnten sich darunter sowohl ROT- als auch geschäftskritische Daten befinden.

Wie bereits angemerkt, könnte sich im Dunkeln ein wahrer Datenschatz verstecken. Daher kann es für Unternehmen von großem (Wettbewerbs-) Vorteil sein, auf ihre Dark Data aufmerksam zu werden und sich diese zu Nutze zu machen. Beispielsweise zeigen sich durch eine Analyse der schlafenden Daten Verbindungen zwischen verschiedenen Datensätzen. Unternehmen können so die Basis für genauere Prognosen legen und wertvolle Geschäftseinblicke gewinnen, die ihnen sonst verborgen geblieben wären. Und das alles mit bereits vorhandenen Daten, die nur auf ihre Verwendung warten.
Doch natürlich bergen diese meist ungeschützten Datenmengen auch ein Sicherheitsrisiko. Unternehmensinterne Daten, darunter vor allem Personendaten, könnten durch mögliche Sicherheitslücken ganz leicht Hackerangriffen zum Opfer fallen. Unternehmen sollten sich daher ihrer Verantwortung bezüglich dieser Daten bewusst werden und sie besser vor potenziellen Gefahren schützen. Eine Analyse der Dark Data würde dies vereinfachen. Die im Dunkeln verborgenen geschäftskritischen und personenbezogenen Daten würden als solche erkannt und könnten sicher verwahrt werden. Die übrigen ROT-Daten könnten, soweit es für sie keine weitere Verwendung gibt, von den Servern gelöscht werden.
Um das versteckte Potenzial in den Dark Data nutzen zu können, müssen diese zunächst gefunden werden. Eine Möglichkeit dafür ist, eine umfassende Bestandsaufnahme aller unternehmerischen Daten zu machen, also ein Datenassessment. Außerdem bietet es sich an, mit den richtigen Tools und Methoden des Data bzw. Information Retrievals gezielt nach konkreten Informationen zu suchen.
Die weitere Analyse dieser unstrukturierten Daten stellt heute kein größeres Hindernis mehr dar, wenn Dark Analytics individuell auf das Unternehmen zugeschnitten wird. Verbesserte Tools können Datensätze miteinander verknüpfen und Unternehmensprozesse automatisieren und beschleunigen. Hier finden auch Lösungen wie Enterprise Search und die Entwicklung von flexiblen Information Governance-Strategien Anwendung.
Postskriptum: Was sind Ihre Erfahrungen mit Dark Data? Wie geht Ihr Unternehmen damit um? Berichten Sie uns doch von Ihren Erfahrungen an info@epic-insights.com – Wir freuen uns darauf!
gefördert durch:
Dann sind WIR genau der richtige Ansprechpartner für Sie!
Treffen Sie uns auf der DMEXCO 2019
am 11. und 12. September
in der Messe Köln
Halle 9.1/ Stand F023
Kontaktieren Sie uns über info@epic-insights.com
Egal, ob Sie mit Ihrer Idee noch ganz am Anfang stehen oder bereits konkrete Vorstellungen für die Analyse und Verarbeitung Ihrer Daten haben:
Unser erfahrenes Data-Science-Team steht Ihnen in den verschiedensten Anwendungsfeldern wie E-Commerce Personalisierung, Social Data oder Custom AI Entwicklung mit Rat und Tat zur Seite.
Wie kann ich meine Daten besser nutzen?
Finden Sie mit Hilfe einer Potential-Analyse die Geschichte in Ihren Daten!
Welche KI-Use-Cases sind für mich möglich?
Entdecken Sie
die Flexibilität von epicAi in den verschiedensten Anwendungsfeldern!
Wie kann ich mein Potential noch weiter ausschöpfen?
Entwickeln Sie mit uns
Ihre perfekte Branchenlösung, von Logistik
bis E-Commerce!
Individuell. Branchenübergreifend. Kompetent.
Haben wir Ihr Interesse geweckt?
Schauen Sie sich hier unsere Best Case Beispiele an und vereinbaren Sie noch heute einen persönlichen Termin über info@epic-insights.com
Ich arbeite hier als Machine Learning-Programmierer und kümmere mich zusätzlich um Datenanalysen. Das heißt, dass ich Informationen und Zusammenhänge aus großen Datenmengen heraushole. Diese Daten können Text, Bilder, Videos oder auch Trackinginformationen sein.
In unseren Projekten geht es darum, Daten in handlungsrelevante Informationen zu verwandeln. Hierfür setzen wir auf modernste Methoden der Datenanalyse und des Machine Learnings, um beispielsweise Vorhersagen zu treffen oder Muster zu erkennen. Mein Ziel ist es, unseren Kunden dabei zu helfen, fundierte Entscheidungen auf Basis von Daten zu treffen und ihr Geschäftspotenzial voll auszuschöpfen.
Darüber hinaus sehe ich es als meine Aufgabe, unsere Kunden bei der Implementierung von Machine Learning-Lösungen zu unterstützen und ihnen das notwendige Know-how zu vermitteln. Denn nur so können sie auch in Zukunft von den Vorteilen datengetriebener Entscheidungen profitieren.
Es ist toll, dass meine Aufgabe einen direkten Mehrwert für unsere Kunden hat. Ich finde diejenigen Informationen, mit denen ihre Angebote, Customer Journeys und strategischen Entscheidungen besser werden.
Meine Daten sind je nach Fragestellung super unterschiedlich. Mich reizt die Vielfalt unserer Beratungsprojekte im Bereich Data Science. Je nach Projekt beschäftige ich mich mit Bildverarbeitung, mit Textanalysen und mit Zeitreihen. Am meisten Spaß macht die Suche nach der passenden Machine Learning-Methode für den jeweiligen Anwendungsfall; denn die unterschiedlichen Algorithmen haben je nach Einsatzbereich ihre Vor- und Nachteile.
Datenanalysen zur Mustererkennung oder Zielgruppensegmentierung beginnen immer mit dem Säubern und Strukturieren der Daten. Anschließend wählen wir Algorithmen aus, die zum Datensatz und der Fragestellung passen.
Dazu gehören auch Performancevergleiche verschiedener Algorithmen im Hinblick auf die spezifischen Kundenherausforderungen und die Möglichkeiten der Datensätze. Die wichtigste Aufgabe ist dabei das modellieren der Daten. Die Modelle, die letztlich im Livebetrieb verwendet werden sollen, um die gesuchten Informationen aus neuen Daten vorherzusagen, müssen dabei auf einen optimalen Fit gebracht werden. Und die Kundendaten sind permanent in Bewegung und Veränderungen unterworfen – genauso müssen die Modelle und Ergebnisse selbst nach Release überwacht und adaptiert werden.
Künstliche Intelligenz ist das übergeordnete Konzept – quasi eher ein Marketing-Buzzword- zu dem auch Machine Learning gehört. Machine Learning-Verfahren sind eine der wichtigsten Voraussetzungen für die systematische Erarbeitung von komplexer KI-Software.
Anm. d. Red.: Bitte beachtet auch unseren bestehenden Beitrag dazu.
Deep Learning ist aktuell sehr populär und sehr stark. Beim Deep Learning wird ein Netzwerk aus unterschiedlichen Neuronen und Schichten zur Mustererkennung eingesetzt. Deep Learning ist ein Teil von Machine Learning. Quasi ein Werkzeug von vielen in meiner Werkzeugkiste. Deep Learning wird sehr häufig z.B. im Zusammenhang mit Bilderkennung eingesetzt, denn dort funktioniert es sehr gut. Auf anderen Daten muss es aber auch nicht das Werkzeug der ersten Wahl sein. Je nach Einsatzbereich funktioniert Deep Learning besser oder schlechter, es kommt immer auf den Anwendungsfall, die Daten und viele andere Faktoren an, die ich im Rahmen des Projektes zur Verfügung habe.
Ein erfolgreiches Projekt steht und fällt nicht nur mit der Auswahl der richtigen Algorithmen und der passenden Datenmodellierung. Die gesamte technische Klaviatur muss korrekt aufeinander eingestellt sein. Bei der Echtzeit-Personalisierung mit Künstlicher Intelligenz zum Beispiel braucht man viel Rechenpower und effiziente Algorithmen, die auf wenigen und teilweise auch sehr dynamischen Daten maximale Ergebnisse ausgeben. Da spielt das Thema Genauigkeit eine große Rolle, die im Sinne einer guten Performance manchmal auch weniger hoch sein muss, wie in anderen Anwendungsfällen. Die Server müssen schnell reagieren.
Die gesamte Wertschöpfung muss penibel aufeinander abgestimmt sein, um hocheffizient zu arbeiten – wie in einem Formel-1-Wagen. Daher müssen alle Systemteile sehr schnell aufeinander reagieren und im Problemfall eben auch die Fallbacks kennen. Vom Tracking, welches die User-Session erkennt, über die eigentliche Vorhersage durch das System bis hin zum ausliefernden Javascript, was den Content in wenigen Millisekunden an den User im Frontend ausgibt – alles muss exakt ineinander greifen, damit der Nutzer selbst nicht irritiert wird, oder die Usability der Website leidet.
Wir sind ein vergleichsweise kleines Team. Dadurch können wir uns sehr schnell abstimmen. Wir bringen ganz unterschiedliche Erfahrungen und Expertisen mit. Das hilft uns bei den sehr unterschiedlichen Projekten und Technologien, mit denen wir jonglieren.
Und ich denke unsere Start-Up-Kultur ist ein Vorteil. Wir dürfen auch mal unkonventionelle Lösungen ausprobieren. Wenn es dem Kunden nützt, dann gibt es eigentlich keine Restriktionen.
Am 24. Januar 2019 überzeugte epicinsights auf der international bekannten Konferenz AI Masters in Berlin mit ihrer Predictive Analytics-Plattform epicAi. Die 11-köpfige Fachjury des AI Masters Publicis Award wählte aus mehr als 100 nationale und internationale Startups epicinsights als Gewinner-Team aus.
„epicinsights konnte nicht nur mit einem innovativen AI Ansatz überzeugen, sondern auch mit der Anwendung der Lösung im Business. Im Rahmen des Auswahlprozesses konnte sich die Jury einen sehr guten Eindruck verschaffen, wie eine Umsetzung für die Partnerunternehmen aussehen und welchen Mehrwert dieser bringen würde.“
AI-MASTERS-Schirmherr René Lamsfuß,
Quelle
Die AI Masters Publicis Challenge gliederte sich in einen mehrstufigen Prozess. Startpunkt war ein Startup Pitch auf der DMEXCO 2018:
Dem Auftakt auf der DMEXCO folgten zwei weitere Pitches, die sich mit dem Einsatz des von epicAi für verschiedene Herausforderungen in den Bereichen E-Commerce und Marketing beschäftigten. Die Präsentationen wurden von der einer 11-köpfigen Jury beurteilt.
Abschließend visualisierten wir unsere Lösungskompetenz am Abend des 24. Januar 2019 mit einem Video. Das hier war unser Beitrag:
„Wir freuen uns riesig über die Auszeichnung und die Bestätigung, dass wir auf dem richtigen Weg sind. Das ist Rückenwind um weiter in den noch sehr jungen KI-Markt vorzudringen. Neben dem Fokus auf den Vertrieb konzentrieren wir uns jetzt auf die konkrete Projektumsetzung mit dem Team von Publicis Media!“
Michael Mörs, CEO
Im Anschluss an die offizielle Preisverleihung folgte direkt ein Videointerview mit Michael. Darin verrät er, wie epicinsights die Jury überzeugte und wofür er das Preisgeld von 25.000€ ausgeben wird:
Die offizielle Pressemitteilung finden Sie hier.
Weiterführende Informationen zu epicAi finden Sie hier.
Wir freuen uns auch über Ihre Zuschriften an info@epic-insights.com.
Pressekontakt:
epicinsights
Jendrik Lutz
Leutragraben 1
Intershop Tower
D-07743 Jena
t: +49 3641 316 99 76
f: +49 3641 573 3301
m: lutz@epic-insights.com
Eine aktuelle KI-Studie zeigt: im Digital-Business wird der Geschäftserfolg entscheidend von einer effizienten und effektiven Personalisierung beeinflusst. Personalisierung meint die nutzerbasierte Ausspielung von Content und Interaktionsmöglichkeiten. Ein typisches Ziel ist z.B. die Optimierung der User-Journey durch Minimierung der Abbruchquote mit Hilfe von personalisierten Empfehlungen.
Dabei ist es nach wie vor nicht leicht, relevante Empfehlungen an den Mann (resp. die Frau) zu bringen. Das Thema Relevanz ist zwar wichtig, gleichzeitig aber auch schwer fassbar und noch viel komplizierter zu messen. Bisher war Relevanz im dynamischen Datenrauschen lediglich über nicht-repräsentative Umfragen oder post-interaktiv anhand fragwürdiger KPIs annährend evaluierbar. Dank KI-Methoden wird sie nun ganzheitlicher, statistisch greifbar.
Künstliche Intelligenz im Bereich der Website-Personalisierung setzt u.a. auf Machine Learning-Algorithmen. Sie ist in der Lage, Content für verschiedene User Journeys optimal auszusteuern. Für jeden Nutzer sagen Künstliche Intelligenz-Anwendungen die relevanteste Next-Best-Action in Echtzeit vorher und lösen entsprechende Prozesse zur Ausspielung des Contents aus. Aber lässt sich eine User Journey wirklich vollumfänglich und mit wenigen Klicks, quasi Plug and Play, personalisieren?
Ob überall dort, wo KI draufsteht, auch wirklich Künstliche Intelligenz drin ist, mag man bezweifeln können. Denn es gibt einige technische Herausforderungen, die bei der Personalisierung von User Journeys mittels Künstlicher Intelligenz zu beachten sind. Eine davon nennen wir den Performance Gap.
Nehmen wir an, die Personalisierungsmethode nutzt als Datengrundlage die große Vielfalt der Verhaltensdaten, welche über Behavior-Tracking kontinuierlich auf der Website bzw. dem Onlineshop eingesammelt wird. Performance Gap bezeichnet in diesem Kontext die Lücke zwischen der vorhandenen und der notwendigen Datenvielfalt (resp. Datenmenge), die ich für ein effektives Training meiner Algorithmen benötige.
Sehr vereinfacht gesagt, brauche ich umfangreiche und gut strukturierte Daten, um Machine Learning-Algorithmen zu trainieren. Auf Grund der Besucherfrequenz einzelner Seiten meines Shops ist die Datendichte für einzelne Schritte einer User Journey jedoch unterschiedlich umfangreich. Prädiktive Algorithmen, die ohne vorherige Sichtung des Daten-Potentials auf verschiedenen Seiten einer Internetpräsenz wahllos implementiert werden, arbeiten unterschiedlich effizient und liefern z.T. unzureichende Resultate. Warum ist das so?
Stellen wir uns vor, wir haben einen Online-Shop mit einer sehr einfachen User-Journey. Diese erstreckt sich von der Startseite über die Kategorien bis zu den Produktseiten. Dort angelangt, kann der Besucher Artikel in den Warenkorb legen und von hier aus den Checkout durchführen.
Bekanntermaßen hat jeder Online-Shop entlang dieses „Funnels“ eine nach hinten heraus stark abnehmende Besucherfrequenz auf einzelnen Seiten. Dies ist zum einen dadurch bedingt, dass es am Anfang des Funnels recht wenige Seiten (z.B. Startseite, Kategorien-Seiten etc.) gibt, welche sich nach hinten heraus in eine Vielzahl an Einzelseiten (z.B. Produktseiten) auffächern. Zum anderen gehen mit jedem Seitenwechsel eine nicht unwesentliche Anzahl von Nutzern verloren – aus diversen Gründen. Ganz am Ende, auf der Success-Page des Checkout, bleiben verhältnismäßig wenige Nutzer pro Tag übrig.
Man kann pauschal sagen: Am Anfang habe ich sehr viele User, über die ich sehr wenige Informationen habe. Im weiteren Verlauf der „Reise“ bis hin zum Kauf bleiben mir nur sehr wenige User erhalten, über die ich jedoch sehr viele Informationen (z.B. CRM-Daten) habe.
Für eine effektive Personalisierung gilt es daher, frühstmöglich folgende Frage zu klären: An welchen Orten meiner Website habe ich einen ausreichenden Datenmix um einen Machine Learning-Algorithmus in die Lage zu versetzen, für jeden Besucher die relevanteste Next-Best-Action vorherzusagen?
Um eine wirkungsvolle Künstliche Intelligenz möglichst ressourceneffizient in meine Website zu integrieren, gilt es zunächst, jene Stellen der User Journeys zu identifizieren, welche das größte Optimierungspotential haben. Wenn diese Quick-Wins einmal realisiert sind, geht es an eine schrittweise Ausweitung der Integration. Strategisch sollte neben der eigentlichen Optimierungsstrecke auch immer das Ziel im Auge behalten werden, dass eine konsolidierte User Journey durch alle Seiten hinweg zu einem kontinuierlicheren Datenstrom führen kann. Dies dient der Erschließung neuer Optimierungscases und fördert die sukzessive Schließung aller Performance Gaps auf meiner Seite.
Seit 2016 ist epicinsights Ihr zuverlässiger Datenspezialist und Technologie-Partner für die Verarbeitung und Analyse von mehrdimensionalen Datenräumen. Unsere Teams aus Projektmanagern, Software-Entwicklern, Data Science- und Machine Learning-Spezialisten begleitet Sie in die Welt der Künstlichen Intelligenz – Hands-on mit Leidenschaft, Zuverlässigkeit und einem nachhaltigen Selbstverständnis.
Berichten Sie uns doch von Ihren Erfahrungen an lutz@epic-insights.com
Wir freuen uns darauf.
Operative und strategische Marketingentscheidungen werden zunehmend auf Grundlage einer reichen Datenfülle getroffen. Bisher wurden Business- und Customer-Intelligence-Systeme jedoch hauptsächlich für eine Top-Down-Betrachtung genutzt. Heute hingegen sind Big Data und Künstliche Intelligenz die zukunftsweisenden Stichworte und ermöglichen Predictive Marketing von unten nach oben, durch die Bottom-Up-Perspektive.
Wenn ich als Marketing- und Sales-Entscheider auf eine Top-Down-Betrachtung zurückgreife, dann betrachte ich verfügbare Informationen mit meinen strategischen Planvorhaben, Erfahrungen und Annahmen aus einer langen Berufspraxis. Das bedeutet: Meine Zielgruppen leite ich aus den bestehenden Kundendaten und Vertriebskanälen ab. Bei der Planung neuer Kommunikationsmaßnahmen erstelle ich also (bewusst oder unbewusst) ein Spiegelbild – quasi ein Best-of – früherer Maßnahmen.
Die Bottom-Up-Perspektive beginnt dagegen bei meinen kleinteiligen Daten, die aus meinen Tracking-Instrumenten heraus generiert werden. Die kleinste Einheit ist hier die Session-ID eines Website- oder Anzeigen-Besuchers. Neugierig schaue ich in der Fülle an Informationen nach Trends und nichtlinearen Zusammenhängen, die statistisch nachweisbar in (m)einem Datenhaufen vorhanden sind. In diesem Fall starte ich die Planung meiner Kommunikationsmaßnahmen nicht bei den Erfolgen vergangener Quartale. Bottom-Up orientiert sich viel stärker an den Bedürfnissen, die mir die Daten meiner digitalen Angebote unmittelbar und in Echtzeit kommunizieren.
Klassischerweise nahm ich als Marketer und Shop-Besitzer eine Top-Down-Betrachtung auf meine potentiellen Kunden ein. Ich suchte in meinem Business Intelligence-Tool und externen Marktforschungsdaten nach den passenden Kennzahlen und überführte diese in meine Strategie. Was kauften meine (potentiellen) Kunden im vergangenen Quartal? Welche Einkommensgruppen gehören zu meiner relevanten Zielgruppe? Welche weiteren sozio-demographischen Merkmale hat welche Gruppe? Damit fand ich hervorragend, wonach ich suchte. Jedoch war der Abstraktionsgrad und die Unschärfe bei diesem Ansatz sehr hoch. Die zentrale Frage: Wie geht man mit Informationen um, die auf Grund der hohen Flughöhe gar nicht erkennbar sind? Welches potentielle Risiko gehe ich ein, essentielle Informationen durch diesen Ansatz nicht wahr-zunehmen? Bin ich mir darüber bewusst, dass ich potentiell wichtige Informationen vernachlässige, weil ich gar nicht weiß, dass es sie gibt?
Für neue Marktanteile brauche ich neue Kunden. Diese erreiche ich mit relevanten Inhalten an relevanten Kontaktpunkten. Mit einer gewissen Erfahrung kenne ich diese, finde meine Nische und die richtigen Stellschrauben, um alle Maßnahmen aufeinander einzustellen. Ich bilde Schablonen und werde effizienter bei der Umsetzung von Maßnahmen. Gleichzeitig laufe ich Gefahr, Trends und Veränderungen zu ignorieren und essentielle Details zu übersehen. Gerade die wahrgenommene Relevanz meiner Themen verändert sich dynamisch – monatlich, wöchentlich, täglich.
Nehmen wir an, das unmittelbare Verhalten meiner Nutzer ist Ausdruck einer abstrakten Kenngröße namens Relevanz, so kann ich dieser KPI Attribute zuordnen und das Thema entsprechend messbar machen. Damit ist es möglich, Kommunikationsmaßnahmen anhand des realen Nutzerverhaltens abzuleiten. Aus der maximal granularen Datenwelt erhalte ich neue Impulse, um regelmäßig aus den Schablonen auszubrechen und neue kommunikative Räume und Zielgruppen zu erschließen.
Im Predictive Marketing wird Top-Down nicht durch Bottom-Up ersetzt. Vielmehr öffne ich meinen strategischen Fokus für große Datenmengen und erweitere meine Perspektive, indem beide Ansätze kombiniert werden. Wenn ich bspw. eine Verkürzung der User-Journeys plane, ermöglicht mir die Untersuchung großer Datenmengen (von Unten nach Oben) die Identifikation der richtigen Ansatzpunkte für diese Verkürzung.
Für einen Informationsgewinn durch die Bottom-Up-Betrachtung brauche ich keine neuen Prozesse, Mitarbeiter, Hardware oder Softskills. Moderne Data Mining-Methoden und webbasierte Reportings ermöglichen den Zugriff auf eine Fülle von neuen Insights, ohne meine bestehenden Geschäftsprozesse durcheinander zu bringen.
Im Bottom-Up-Prozess gewonnene Information können die Grundlage für die Erstellung rein datengetriebener, auf echten Verhaltensdaten basierender Personas sein. Diese sind realistischer als klassische Buyer Personas, die aus Marktforschungsabteilungen kommen oder auf einem Bauchgefühl beruhen.
Mit Hilfe meiner Bottom-Up-Perspektive gewinne ich erstaunliche Einblicke. Und das mit Daten, die ich jeden Tag über meine Website und weitere digitale Kanäle frei Haus geliefert bekomme. Ich erhöhe somit die Vielfalt meiner Marketing-Optionen. Ich erhalte realistischere Informationen über mögliche Entwicklungsfelder und erkenne schneller die Veränderung von Prioritäten.
Alles, was ich dazu brauche, ist ein Abbild von den Besuchern meiner Seite bzw. meines Shops, welches die Verhaltensdaten ALLER Nutzer (unabhängig ob Kunde oder Nicht-Kunde) berücksichtigt. epicinsights nennt diese Form der Nutzerklassifiaktion Fluide Persona.
Mit der Bottom-Up-Perspektive auf fluide Personas gestalte ich mein Marketing zeitgemäß und kann schnell und zielgerichtet auf Veränderungen im Kundenverhalten reagieren. Gleichzeitig ersetzt künstliche Intelligenz nicht meine kreative Arbeit, meine strategische Geschäftsausrichtung und mein Wissen über Marktbedingungen und Konkurrenten. Vielmehr komplementieren Bottom-Up-Informationen klassische Top-Down-Prozesse.
Wie sind Ihre bisherigen Erfahrungen mit Predictive Marketing? Berichten Sie uns doch von Ihren Erfahrungen an lutz@epic-insights.com – Wir freuen uns darauf.
Laut Statistischem Bundesamt sind rund 96% aller Unternehmen in Deutschland sogenannte kleine und Kleinstunternehmen mit weniger als 50 Mitarbeitern. Eine technologisch orientierte Effizienzsteigerung ist für diese Unternehmen existentiell, denn sie operieren mit einem begrenzten Maß an finanziellen und personellen Ressourcen. Gleichzeitig stehen sie durch das Internet und eine fortschreitende Globalisierung in einem übernationalen Konkurrenzkampf.
Im Allgemeinen sind die Gründe für KI in KMU neben dem zunehmenden Wettbewerb auch ein erhöhter Kostendruck zu Lasten der Unternehmen. Mehrkosten können oftmals nicht an Kunden weitergegeben werden. Umsatz- und Ertragssteigerungen sollen diese Aufwände daher bei gleichbleibenden Mitarbeitereinsatz egalisieren.
Ein großer deutscher Hersteller für Sportbekleidung setzt deswegen bereits heute auf vollautomatisierte Fabriken. Die Produktivität ist dort 5x höher als im Industriedurchschnitt. Das ist ein eindringliches Beispiel für maschinengestützte Effizienzsteigerung auf deutschem Boden.
Einem aufmerksamen Marketer wird nicht entgangen sein, dass Entwicklungen wie Industrie 4.0 oder auch Big Data-Analytics mit dem Versprechen der Effizienzsteigerung durch Digitalisierung eng verwoben sind. In diesem Beitrag lesen Sie, wie Effizienzsteigerungen durch KI-orientierte Prozessoptimierung möglich werden; zunächst gibt es jedoch eine Begriffserklärung.
Der Einsatz von Künstlicher Intelligenz in KMU betrifft vor allem die Ausgestaltung von Geschäftsprozessen auf eine Weise, dass der Wirkungsgrad dieser Geschäftsprozesse optimiert wird. Ziel von KI in KMU ist ein gleichbleibend hoher oder sogar erhöhter (wirtschaftlicher) Ertrag bei gleichzeitig vermindertem Einsatz von finanziellen Ressourcen oder Mitarbeitern.
Häufig werden die Begriffe Optimierung, Produktivitätssteigerung oder auch Effektivitätssteigerung als Synonyme für diese Effizienzsteigerung verwendet.
Wenn ich als Unternehmer Potenziale der Effizienzsteigerung angehen möchte, dann habe ich im Grunde drei Möglichkeiten: Effizienzsteigerung durch Software, Automatisierung oder Prozessoptimierung.
Tätigkeiten und Aufgaben werden vereinfacht, um (auch mentale) Umrüstzeiten zu verringern. Ihre Mitarbeiter arbeiten mit Softwarelösungen, die ihnen Arbeitsprozesse intelligent abnehmen und damit die Effizienz Ihres Unternehmens steigern. Mehrstufige Business-Prozesse müssen nicht kompliziert sein. Ein durchdachtes Tool kann Ihren Kollegen somit aufwendige Arbeitsschritte abnehmen und sie schneller an das Ziel Ihrer Wertschöpfungskette bringen. Dies wird mittelfristig und in mehreren iterativen Projekten zur Integration selbstlernender Algorithmen innerhalb Ihrer digitalen Prozess-Landschaft führen.
Bei der Effizienzsteigerung durch Prozessoptimierung werden Datenströme solange harmonisiert, bis die Informationen der einzelnen Prozessschritte nahtlos ineinandergreifen. Diese Maßnahme der Effizienzsteigerung ist besonders mit dem Aufstieg der modernen Fließbandproduktion verknüpft und führt bis heute zur Neuausrichtung organisatorischer und technischer Prozesse.
Ein verbesserter Wirkungsgrad wird dabei durch einen verbesserten Input von Ressourcen, eine optimierte Mechanik innerhalb der Geschäftsprozesse und eine Maximierung des Ertrags erreicht. Im Hinblick auf den Aufstieg Künstlicher Intelligenz (KI) ist jene Effizienzsteigerung durch Prozessoptimierung eine Option, die wohl als nachhaltigste Form der Effizienzsteigerung bezeichnet werden kann.
Besonders im Bereich des Data Strategy Development ist Prozessoptimierung ein Trendthema. Datengetriebene Dokumentenverarbeitung oder Marketing Automation sind typische Beispiele für eine datengestützte Effizienzsteigerung bzw. KI in KMU.
Viele Arbeitsmittel und Ressourcen in Unternehmen sind nur begrenzt verfügbar (z.B. Zeit, Rechenkapazitäten, Know-How etc.). Anders ist dies bei Daten und Informationen. Diese sind kostenlos und werden stündlich neu generiert. Jede Interaktion eines potenziellen Kunden mit unserer Website oder unseren Social-Media-Inhalten ist eine wertvolle Information. Daher ist der Bereich des Zielgruppenmarketings prädestiniert für eine Transformation.
Die Möglichkeiten zur Effizienzsteigerung beginnen bei einer KI-gestützten Zielgruppenanalyse und erstrecken sich bis zur dynamischen, individualisierten und vollautomatischen Konvertierung.
Die Nachhaltigkeit von KI in KMU steht und fällt mit den Mitarbeitern. Sie tragen die Effizienzsteigerung von Prozessen. Aus diesem Grund ist es sinnvoll die Mitarbeiter mitzunehmen. Künstliche Intelligenz und Data Analytics sollen ihre Arbeit ergänzen und nicht ersetzen. In einem ersten Schritt kann ich den Prozess aus Recherche, Datenerhebung, Gewichtung und Zielgruppensegementierung mit entsprechenden Softwarelösungen und statistischen Verfahren vereinfachen.
Schließlich bietet dieser Prozess noch weitere Optimierungsstufen. Die Ergebnisse dieser Zielgruppensegmentierungen lassen sich vollautomatisch weiterverwenden, sodass Algorithmen passende Produkte anbieten oder sogar ganze Webseiten und Informationsangebote individuell und in Echtzeit optimieren. Mit agilen Projekt-Methoden werden die ersten „Quick Wins“ auf weitere Cases erweitert – entweder vertikal und/oder horizontal.
epicinsights ermöglicht datengetriebene Erkenntnisse durch eine einzigartige Kombination von Softwarelösungen und statistischen Verfahren zur Erfassung und Verarbeitung anonymer Verhaltensdaten: epicAi. Dieses Big Data Infrastruktur-Framework untersucht große, komplexe und dynamische Datenmengen automatisch, datengetrieben und in Echtzeit auf Ähnlichkeitsstrukturen, Querverbindungen und Trends.
Unser erfahrenes Team aus Projektmanagern, Software-Entwicklern, Data Science- und Machine Learning Spezialisten begleitet Sie in die Welt der künstlichen Intelligenz und liefert maßgeschneiderte Machine Learning basierte Individual-Lösungen entlang Ihrer digitalen Wertschöpfung.
Wann immer ich in den letzten Jahren auf KI-Konferenzen gewesen bin, kam früher oder später die Sprache unweigerlich auf Business Intelligence und Big Data. Doch wie passt das zusammen? Wo sind Überschneidungen und auf welche Veränderungen müssen wir uns einstellen? Wir waren uns immer einig, dass Big Data für alle Geschäftsprozesse ein heißes Thema ist. Deswegen möchte ich hier die wichtigsten Entwicklungen kurz nachzeichnen.
Die Geschäftsanalyse mit einer Strategic Intelligence-Software ermöglicht die Verbindung von Warenwirtschaft, Customer-Relationship-Management und weiteren Daten in elektronischer Form. Für eine Vielzahl von Fragestellungen liefert mir ein BI-Tool rückblickende Informationen und eine endliche Menge an Diagrammen bzw. Antworten.
Business Intelligence eignet sich aus diesem Grund vor allem zur Beschreibung von Kundengruppen, Durchschnittswerten oder einfachen linearen Zusammenhängen.
Im Gegensatz zum Zugriff auf Kennzahlen beschreibt Big Data viel mehr eine besondere Notwendigkeit im Umgang mit komplexen und dynamischen Datenmengen. Um diese Datenströme effizient auszulesen und zu explorieren, reichen klassische Datenbanktechnologien und einfache Regressionsmodelle nicht mehr aus. Solche Daten werden mit Big Data Analytics und Machine Learning-Methoden näher untersucht, um verborgene Zusammenhänge und Muster zu erkennen.
Mit BI-Tools bekomme ich also eine rein deskriptive Zusammenfassung der aktuellen Situation bzw. Vergangenheitsdaten. Ich erhalte damit Antworten auf die Frage nach dem „Was“. Sobald ich aus diesem Datenrauschen Vorhersagen und Zusammenhänge extrahieren und diese automatisch interpretieren möchte, ist klassisches „BI“ unzureichend. Die Frage nach dem „Warum“ und mögliche Handlungsableitungen aus diesen Erkenntnissen bleibt beim BI außen vor.
Im KI-Zeitalter werden BI-Ansätze um die essentielle Frage nach dem „Warum“ ergänzt. Beschreibende Business Intelligence-Informationen werden mit dem maschinenbasierten „Schürfen“ nach verborgenen Erkenntnissen erweitert. Neu erkannte Zusammenhänge unterstützen mich somit deutlich effektiver bei der Suche nach Optimierungspotentialen in meiner gesamten Wertschöpfung oder Wettbewerbsvorteilen am Markt.
Advanced Analytics-Methoden und Maschinelles Lernen helfen mir also zeitsparend, das „Wie“ und „Warum“ in meinen Daten besser zu verstehen.
Je komplexer die Datenmengen, desto größer ist der mögliche Informationsgewinn. Durch eine enge Verzahnung von Advanced Analytics und Big Data-Methoden ermöglicht epicinsights eine enorme Informationsdichte. Dieses engmaschige Netzwerk aus Informationen und die darin verwobenen Beziehungen machen wir zu Ihrem einzigartigen Wettbewerbsvorteil!
Für jeden Kunden nutzen wir unsere modulare Predictive Analytics-Plattform epicAi. Diese Zusammenstellung unterschiedlicher technologischer Komponenten gewährleistet eine tiefgehende Identifikation Ihres Datenpotentials und signifikanter Zusammenhänge. Wir verarbeiten und strukturieren große Datenmengen in Echtzeit und können damit u.a. relevante Targeting-Prozesse personalisieren.
Postskriptum: Für welche Fragestellungen arbeiten Ihre Marketing- und Sales-Entscheider mit Business Intelligence-Tools? Berichten Sie uns doch von Ihren Erfahrungen an lutz@epic-insights.com – Wir freuen uns darauf.