Wissensbasierte KI-Systeme (RAG) verändern die Art, wie Unternehmen Wissen nutzen. Doch wenn der ROI ausbleibt oder das KI-Projekt zu scheitern droht, liegt das selten am Basismodell. Es liegt an unsichtbaren Fehlerquellen in der RAG-Architektur.
RAG-Systeme kombinieren zwei grundlegend verschiedene Mechanismen. Das Retrieval – also das Suchen und Ranking relevanter Textfragmente – ist bei gleichem Index und gleichen Parametern reproduzierbar. Die LLM-Komponente dahinter ist probabilistisch: gleiche Eingabe, unterschiedliche Antwort. Diese Unterscheidung ist entscheidend für jede sinnvolle Qualitätssicherung, weil sie bestimmt, wo und wie man misst. Für Sie als Entscheider bedeutet das: Sie benötigen neue, systematische Messmethoden, um die Performance Ihrer generativen KI aktiv zu steuern.
Der strategische Pain Point bei RAG Systemqualität liegt dabei nicht in der Technologie selbst, sondern in der Messbarkeit des Business-Impacts. Eine signifikante Effizienzsteigerung in Unternehmen durch KI lässt sich nur dann nachhaltig realisieren, wenn der Übergang vom Pilotprojekt zum produktiven Betrieb prozesssicher validiert wird. Ohne ein dediziertes Framework für AI-Evaluations riskieren Sie „Silent Failures“ – schleichende Qualitätsverluste in der RAG-Pipeline oder veränderte Modell-Antworten, die erst auffallen, wenn das Nutzervertrauen bereits erodiert ist oder die operativen Kosten unkontrolliert skalieren.
Echte Wertschöpfung entsteht erst dann, wenn technologische Exzellenz und strategische Governance ineinandergreifen. Bei SMADEV verstehen wir Qualitätssicherung (AI-Evals) daher nicht als reaktive Fehlerkorrektur, sondern als proaktives Steuerungsinstrument. Wir laden Sie ein, die Komplexität Ihrer KI-Infrastruktur nicht als Black-Box, sondern als optimierbare Wertschöpfungskette zu begreifen. Nur wer die Validierungskette vom „Research to Revenue“ beherrscht, transformiert technisches Potenzial in messbare Marktführerschaft.
Key-Takeaway:
„Nachhaltige Effizienzsteigerung erfordert dynamische AI-Evaluations. So machen Sie die Verlässlichkeit und Kapitalallokation Ihrer Systeme jederzeit steuerbar.“
Jetzt Whitepaper herunterladen
Wie systematische AI-Evaluations
die Qualität Ihres RAG Systems überwachen.

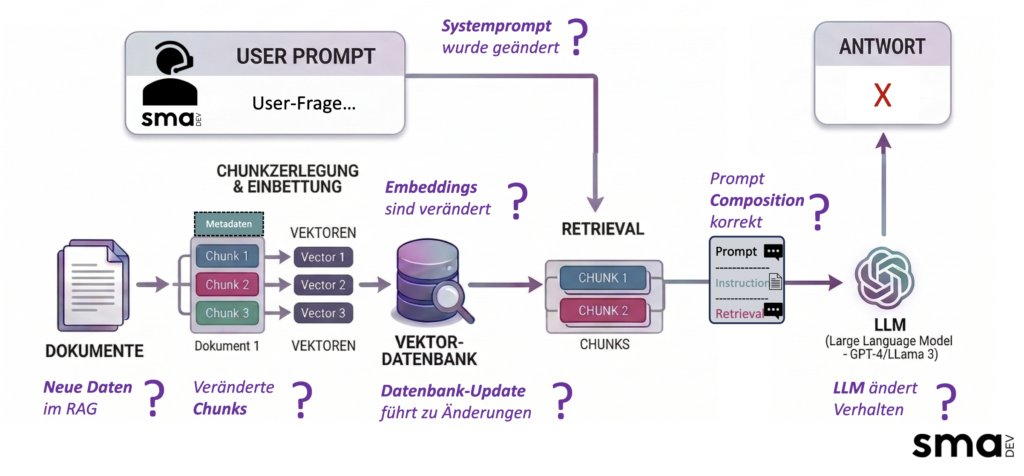
Das Diagramm zeigt, wo in einer RAG-Pipeline Fragen entstehen und damit auch, wo Fehler entstehen können. Jede Station zwischen Dokument und Antwort ist eine potenzielle Fehlerquelle: neue Daten verändern den Index, veränderte Chunks verschieben was das System findet, ein Datenbank-Update beeinflusst das Ranking, eine minimale Anpassung im Systemprompt verändert wie das LLM die abgerufenen Fragmente verarbeitet. Die Antwort am Ende der Pipeline ist das Ergebnis all dieser Zwischenschritte, sichtbar, aber oft ohne erkennbaren Bezug zu dem, was tatsächlich schiefgelaufen ist.
Jede dieser Stationen kann Fehler einschleusen und jede lässt sich mit den richtigen Messpunkten überwachen:
Diese dynamische Anpassungsfähigkeit ist die größte Stärke Ihres Systems. LLMs reagieren flexibel auf jede Nutzeranfrage. Die technologische Herausforderung besteht also darin, diese Dynamik so zu orchestrieren, dass sie innerhalb definierter Leitplanken agiert.
Die Beherrschung dieser dynamischen Kette ist der Schlüssel, um tatsächlich Effizienzsteigerung in Unternehmen durch KI freizusetzen.
Qualitätssicherung für RAG-Systeme bedeutet nicht, eine einzelne Kennzahl zu überwachen. Fünf Dimensionen decken zusammen ab, wo ein System versagen kann.
Antwort & Outcome prüft die finale Ausgabe: Ist die Antwort korrekt, vollständig und für den Nutzer verwertbar? Das ist die sichtbarste Dimension, aber auch die, die am wenigsten verrät, wo ein Problem entstanden ist.
Grounding & Wissen fragt, ob die Antwort durch die abgerufenen Quellen gedeckt ist. Ein Modell kann eine überzeugende Antwort formulieren, die im abgerufenen Kontext keine Grundlage hat. Diese Dimension macht genau das sichtbar.
Agent & Tooling wird relevant, sobald das System nicht nur antwortet, sondern Aktionen ausführt, API-Calls, Datenbankabfragen, Werkzeugaufrufe. Hier misst man, ob das richtige Tool aufgerufen wurde, mit den richtigen Parametern, im richtigen Moment.
Conversation bewertet das Verhalten über mehrere Gesprächsrunden: Behält das System den Kontext korrekt bei, löst es Folgefragen konsistent auf, und bricht es nicht aus seinem definierten Verhalten aus?
Operational Quality betrachtet das System unter Betriebsbedingungen, Latenz, Token-Verbrauch, Fehlerrate, Stabilität unter Last. Das ist die Dimension, die direkt auf TCO und Skalierbarkeit einzahlt.
Es geht im ersten Schritt darum, ein Bewusstsein für diese Teilschritte zu entwickeln. Wir platzieren die Messpunkte exakt dort, wo sie Wertschöpfung sichern. Das Resultat ist ein System, dessen Verhalten nachvollziehbar ist und dessen Abweichungen früh sichtbar werden, bevor sie im Betrieb auffallen.
Das Verständnis für die dynamischen Herausforderungen moderner KI-Systeme ist für Entscheider weit mehr als eine technische Notwendigkeit, es ist das Fundament für eine nachhaltige Investment-Strategie. Wenn wir die herkömmlichen Pfade der Qualitätssicherung verlassen und die spezifische Logik von LLM-Pipelines adaptieren, transformieren wir KI von einem experimentellen IT-Projekt in ein skalierbares Business-Asset.
Für die Geschäftsführung bedeutet dieses Bewusstsein den entscheidenden Vorsprung: Es geht darum, die Effizienzsteigerung in Unternehmen durch KI nicht dem Zufall zu überlassen, sondern sie durch professionelles Engineering steuerbar zu machen. Wer die Komplexität der Datenkette heute als gestaltbare Variable begreift, sichert sich die Handlungsfähigkeit für die Skalierung von morgen.
Die Identifikation dieser technologischen Hebel zahlt unmittelbar auf die wirtschaftlichen Kernziele Ihres Unternehmens ein.
Durch das tiefgreifende Verständnis der RAG-Mechanik sichern Sie Ihre Investitionen langfristig ab. Sie entwickeln keine flüchtigen Prototypen, sondern bauen eine robuste Infrastruktur auf, deren Wert auch bei Modell-Updates durch Drittanbieter stabil bleibt.
Ein präzises Bewusstsein für die Abläufe in der Pipeline ermöglicht es, Ineffizienzen, wie etwa unnötig hohe Token-Verbräuche oder redundante Abfragen, frühzeitig zu identifizieren. Das senkt die operativen Kosten und schützt Ihre P&L vor unvorhersehbaren Skalierungseffekten.
Systematische Evals schonen Ihre Experten-Ressourcen und beschleunigen den Go-live. Ein proaktives Verständnis der Systemdynamik verkürzt die Zeitspanne von der Entwicklung bis zur Marktreife (Time-to-Market) massiv.
RAG + AI-Evals erhöhren Transparenz und Qualität
In einem Marktumfeld, das oft noch von intransparenten „Black-Box“-Lösungen geprägt ist, wird die nachweisbare Beherrschung der Technologie zum zentralen Differenzierungsmerkmal. Vertrauen in die KI-Output-Qualität ist die härteste Währung im B2B-Sektor.
SMADEV unterstützt Sie dabei, diese technologischen Herausforderungen nicht als Barrieren, sondern als exklusive Chance zur Wertschöpfung zu nutzen. Indem wir die Dynamik von RAG-Systemen als beherrschbare Prozesskette definieren, legen wir den Grundstein für eine KI-Lösung, die nicht nur technisch überzeugt, sondern einen harten und messbaren ROI liefert.
Die dynamische Natur von Sprachmodellen ist der entscheidende Hebel für Ihre KI-Strategie. Nutzen Sie diese Flexibilität, um das Fundament für echte Effizienzsteigerung durch KI zu legen. Wer versteht, an welchen Stellen seine RAG-Pipeline variiert und wer dafür Messpunkte definiert hat, kann auf Änderungen reagieren, bevor sie Nutzer bemerken. Durch systematisches Eval-Management machen wir aus Ihrem Prototyp ein robustes Business-Asset, das dauerhaft Wert generiert.
Wer seine RAG-Pipeline versteht, senkt Entwicklungskosten und vermeidet teure Überraschungen im Betrieb. Unternehmen, die Retrieval-Qualität und Token-Verbrauch aktiv messen, steuern ihre KI-Investition, alle anderen verwalten sie.
Erfahren Sie mehr über unsere Methodik:
Unser AI-Evals-Ansatz übersetzt komplexe Datenarchitekturen systematisch in wertschöpfende, steuerbare KI-Produkte.
Lassen Sie uns den nächsten Schritt gemeinsam gehen.
Steht Ihr RAG-System vor dem Go-live oder läuft es bereits und Sie fragen sich, ob die Qualitätssicherung hält was sie verspricht?
Jetzt kostenfreies Strategiegespräch vereinbaren und konkreten Nutzen für Ihr Unternehmen prüfen
Das Problem liegt meist nicht im Sprachmodell, sondern davor. Falsches Chunking zerschneidet relevante Informationen so, dass kein einzelnes Fragment die Antwort vollständig enthält. Fehlende Metadaten verhindern gezieltes Filtern. Veraltete Dokumente ohne Versionierung liefern korrekt klingende, aber längst überholte Antworten. Das Modell halluziniert nicht, es arbeitet mit dem, was das Retrieval ihm gibt.
Die häufigsten: schlechte Datenqualität im Quelldokument (Duplikate, Widersprüche, veraltete Inhalte), falsches Chunking (zu groß oder zu klein), fehlende oder inkonsistente Metadaten, ein Systemprompt der mit abgerufenen Fragmenten kollidiert, sowie Index-Updates ohne anschließende Retrieval-Tests. Jede Fehlerquelle erzeugt andere Symptome und braucht eigene Testabdeckung.
Die Fehlerquellen in einer „Black-Box RAG“ sind vielfältig und oft unsichtbar (Silent Failures):
Ja, bei stabilem Index, stabilem Embedding-Modell und stabilen Parametern ist Retrieval reproduzierbar. Andere Ergebnisse bei gleicher Frage entstehen nur nach einem Index-Update oder Modell-Wechsel. Deshalb sind Index-Updates die kritischen Ereignisse, nach denen Retrieval-Tests erneut laufen müssen. Die nicht-deterministische Komponente im System ist ausschließlich das LLM.
Bestehende Vektoren behalten ihre Position im Vektorraum. Neue Dokumente erweitern den Suchraum, sie verschieben nichts. Was sich ändert: Bei bestimmten Abfragen können neu hinzugefügte Dokumente jetzt relevanter erscheinen als bisher abgerufene Fragmente. Das kann gewollt sein oder ein Problem, wenn veraltete Inhalte nicht entfernt wurden.
Hier wird nach Dimensionen unterschieden. Je nach Use Case sind diese unterschiedlich gewichtet, dabei ist nicht jede Dimension immer gleich relevant. Zu ihnen gehört: Antwort & Outcome, Grounding & Wissen, Agent & Tooling, Conversation und Operational Quality.
Spätestens bevor ein RAG-System in Produktion geht. Ohne Evals merkt man Qualitätsverluste erst, wenn Nutzer sie melden, zu dem Zeitpunkt hat das System bereits Vertrauen verbraucht.
Die Kosten: erneute Entwicklungszyklen, ungeplante Hotfixes, und im schlimmsten Fall ein System das intern als unzuverlässig gilt und nicht genutzt wird. Ein Testfragenset mit 50 bis 100 Fragen und definierten Referenzantworten ist der minimale Einstieg und lässt sich in einem Sprint aufbauen.