In fast jedem Discovery-Gespräch kommt derselbe Moment: Das RAG-System läuft seit Wochen in Produktion, die Entwickler sind zufrieden, das Management hat abgenickt. Dann fragt jemand das System nach einem internen Prozess und bekommt eine Antwort, die sachlich klingt, aber veraltet ist. Niemand hat es gemeldet. Niemand hat es gemessen.
Das ist kein Einzelfall. Qualitätsverluste in RAG-Systemen entstehen meist schleichend — und sie fallen spät auf.
Der häufigste Denkfehler beim Thema RAG-Qualität: das gesamte System wird als unvorhersehbar abgestempelt. Das stimmt so nicht und wer das glaubt, misst an den falschen Stellen.
Ein RAG-System besteht aus zwei strukturell verschiedenen Komponenten. Der Retrieval-Teil verhält sich bei stabilem Index, stabilem Embedding-Modell und stabilen Parametern reproduzierbar. Gleiche Frage, gleicher Index, gleiche Konfiguration: gleiche Fragmente. Die Variabilität kommt ausschließlich vom Sprachmodell dahinter. Gleiche Eingabe, unterschiedliche Antwort.
Wenn eine Frage plötzlich andere Fragmente liefert als vorher, liegt das nicht an der Natur des Systems. Es liegt an einer Änderung: ein Index-Update, ein neues Embedding-Modell, veränderte Parameter. Das ist wichtig, weil es bedeutet: Index-Updates sind kritische Ereignisse. Nach jedem davon müssen Retrieval-Tests neu durchlaufen werden.
Neue Dokumente verschieben übrigens nicht den gesamten Suchraum. Bestehende Vektoren behalten ihre Position. Neue Dokumente erweitern den Raum — bei bestimmten Abfragen können sie jetzt relevanter erscheinen als bisher abgerufene Fragmente. Das kann gewollt sein. Es wird zum Problem, wenn veraltete Inhalte nicht entfernt wurden.
Der strategische Pain Point bei RAG Systemqualität liegt dabei nicht in der Technologie selbst, sondern in der Messbarkeit des Business-Impacts. Eine signifikante Effizienzsteigerung in Unternehmen durch KI lässt sich nur dann nachhaltig realisieren, wenn der Übergang vom Pilotprojekt zum produktiven Betrieb prozesssicher validiert wird. Ohne ein dediziertes Framework für AI-Evaluations riskieren Sie „Silent Failures“.
Wertschöpfung kann dann entstehen, wenn Technologie und strategische Governance ineinandergreifen. Bei SMADEV verstehen wir Qualitätssicherung (AI-Evals) daher nicht als reaktive Fehlerkorrektur, sondern als proaktives Steuerungsinstrument. Wir laden Sie ein, die Komplexität Ihrer KI-Infrastruktur nicht als Black-Box, sondern als optimierbare Wertschöpfungskette zu begreifen. Nur wer die Validierungskette beherrscht, transformiert technisches Potenzial.
Key-Takeaway:
„Nachhaltige Effizienzsteigerung erfordert dynamische AI-Evaluations. So machen Sie die Verlässlichkeit und Kapitalallokation Ihrer Systeme jederzeit steuerbar.“
Jetzt Whitepaper herunterladen
Wie systematische AI-Evaluations
die Qualität Ihres RAG Systems überwachen.

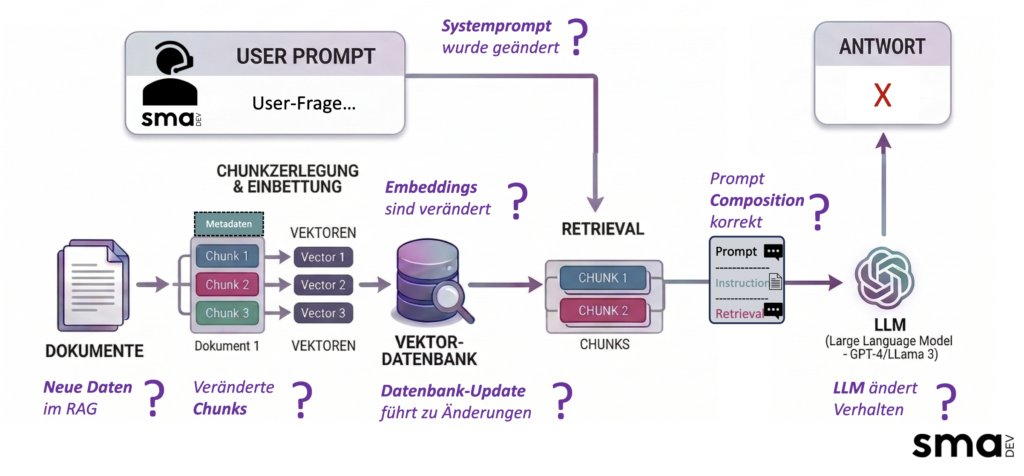
Zwischen Dokument und fertiger Antwort gibt es mehrere Stationen. Jede davon ist eine potenzielle Fehlerquelle, mit eigenen Symptomen und eigener Testabdeckung.
Schlechte Datenqualität im Quelldokument: Duplikate, Widersprüche, veraltete Inhalte ohne Versionierung. Das Modell halluziniert hier nicht, es arbeitet mit dem, was das Retrieval ihm gibt. Korrekt klingende, aber längst überholte Antworten sind das direkte Ergebnis.
Falsches Chunking: Zu große Chunks verwässern die Relevanz. Zu kleine verlieren den Kontext. Kein Embedding-Modell kann reparieren, was schon beim Segmentieren kaputtgegangen ist.
Fehlende oder inkonsistente Metadaten: Ohne saubere Metadaten ist gezieltes Filtern nicht möglich. Das System findet Fragmente, aber nicht die richtigen.
Systemprompt-Kollision: Eine minimale Anpassung im System-Prompt kann dazu führen, dass das Modell die abgerufenen Fragmente anders verarbeitet, Tonalität wechselt, Detailtiefe variiert, Antworten werden unvollständig. Die Quellfragmente sind korrekt, das Ergebnis trotzdem falsch.
Modell-Updates durch den Anbieter: Externe Modell-Updates verändern das Verhalten ohne jede Ankündigung. Ohne laufende Evals merkt man das erst, wenn Nutzer es melden.
Die Grafik zeigt, wo in einer RAG-Pipeline Fragen entstehen und damit auch, wo Fehler entstehen können. Jede Station zwischen Dokument und Antwort ist eine potenzielle Fehlerquelle: neue Daten verändern den Index, veränderte Chunks verschieben was das System findet, ein Datenbank-Update beeinflusst das Ranking, eine minimale Anpassung im Systemprompt verändert wie das LLM die abgerufenen Fragmente verarbeitet. Die Antwort am Ende der Pipeline ist das Ergebnis all dieser Zwischenschritte, sichtbar, aber oft ohne erkennbaren Bezug zu dem, was tatsächlich schiefgelaufen ist.
Viel Diskussion über Evaluation, wenig Konkretheit darüber, was gemessen wird. Fünf Dimensionen decken zusammen ab, wo ein RAG-System versagen kann:
Antwort & Outcome prüft die finale Ausgabe: Ist die Antwort korrekt, vollständig, für den Nutzer verwertbar? Das ist die sichtbarste Dimension, sie verrät aber am wenigsten darüber, wo das Problem entstanden ist.
Grounding & Wissen fragt, ob die Antwort durch die abgerufenen Quellen gedeckt ist. Konkret: Halluzinationsrate, Quelltreue, Antworttreue. Ein Modell kann eine überzeugende Antwort formulieren, die im abgerufenen Kontext keine Grundlage hat.
Agent & Tooling wird relevant, sobald das System nicht nur antwortet, sondern Aktionen ausführt: API-Calls, Datenbankabfragen, Werkzeugaufrufe. Hier prüft man, ob das richtige Tool mit den richtigen Parametern zum richtigen Zeitpunkt aufgerufen wurde.
Conversation bewertet das Verhalten über mehrere Gesprächsrunden: Behält das System den Kontext korrekt bei? Löst es Folgefragen konsistent auf?
Operational Quality betrachtet das System unter realen Betriebsbedingungen: Latenz, Token-Verbrauch, Fehlerrate, Stabilität unter Last. Diese Dimension zahlt direkt auf Betriebskosten und Skalierbarkeit ein.
Je nach Use Case sind diese Dimensionen unterschiedlich zu gewichten. Ein internes Wissenssystem braucht starkes Grounding. Ein Agentensystem braucht starkes Tooling-Monitoring. Kein System braucht alle fünf gleich stark.
Eines vorab: RAG allein kann keine absolute Verlässlichkeit, Revisionssicherheit oder volle Kontrolle garantieren. Wer das verspricht, verspricht zu viel. Was RAG in Kombination mit systematischen Evals leistet: Transparenz über das Systemverhalten und messbare Qualität, beides zusammen macht das System steuerbar.
Ein Testfragenset mit 50 bis 100 Fragen und definierten Referenzantworten ist der minimale Einstieg. Das lässt sich in einem Sprint aufbauen. Die Retrieval-Qualität, also ob das System die erwarteten Quellen findet, lässt sich damit direkt messen.
Die Kosten, Evals wegzulassen: erneute Entwicklungszyklen, ungeplante Hotfixes, und im schlechtesten Fall ein System, das intern als unzuverlässig gilt und nicht genutzt wird.
Wer Retrieval-Qualität und Token-Verbrauch aktiv misst, steuert seine KI-Investition. Wer es nicht tut, verwaltet sie.
Läuft bei Ihrem RAG-System nach jedem Index-Update automatisch ein Retrieval-Test? Wenn nicht, ist das der sinnvolle erste Schritt — sprechen Sie uns an.
Die Beherrschung dieser dynamischen Kette ist der Schlüssel, um tatsächlich Effizienzsteigerung in Unternehmen durch KI freizusetzen.
Qualitätssicherung für RAG-Systeme bedeutet nicht, eine einzelne Kennzahl zu überwachen. Fünf Dimensionen decken zusammen ab, wo ein System versagen kann.
Antwort & Outcome prüft die finale Ausgabe: Ist die Antwort korrekt, vollständig und für den Nutzer verwertbar? Das ist die sichtbarste Dimension, aber auch die, die am wenigsten verrät, wo ein Problem entstanden ist.
Grounding & Wissen fragt, ob die Antwort durch die abgerufenen Quellen gedeckt ist. Ein Modell kann eine überzeugende Antwort formulieren, die im abgerufenen Kontext keine Grundlage hat. Diese Dimension macht genau das sichtbar.
Agent & Tooling wird relevant, sobald das System nicht nur antwortet, sondern Aktionen ausführt, API-Calls, Datenbankabfragen, Werkzeugaufrufe. Hier misst man, ob das richtige Tool aufgerufen wurde, mit den richtigen Parametern, im richtigen Moment.
Conversation bewertet das Verhalten über mehrere Gesprächsrunden: Behält das System den Kontext korrekt bei, löst es Folgefragen konsistent auf, und bricht es nicht aus seinem definierten Verhalten aus?
Operational Quality betrachtet das System unter Betriebsbedingungen, Latenz, Token-Verbrauch, Fehlerrate, Stabilität unter Last. Das ist die Dimension, die direkt auf TCO und Skalierbarkeit einzahlt.
Es geht im ersten Schritt darum, ein Bewusstsein für diese Teilschritte zu entwickeln. Wir platzieren die Messpunkte exakt dort, wo sie Wertschöpfung sichern. Das Resultat ist ein System, dessen Verhalten nachvollziehbar ist und dessen Abweichungen früh sichtbar werden, bevor sie im Betrieb auffallen.
Wer weiß, an welchen Stellen sein RAG-System variiert und dort Messpunkte gesetzt hat, erlebt drei konkrete Verschiebungen:
Aus Hotfixes werden geplante Updates. Qualitätsprobleme tauchen nicht mehr als Überraschung auf, wenn Nutzer sich beschweren. Sie sind sichtbar, bevor sie jemand bemerkt — und lassen sich in den normalen Entwicklungszyklus einplanen statt als ungeplante Feuerwehreinsätze abzuarbeiten.
Modell-Updates durch Drittanbieter verlieren ihren Schrecken. Wer eine Eval-Suite hat, läuft sie nach jedem externen Update und weiß innerhalb von Stunden, ob sich das Systemverhalten verändert hat. Ohne Evals ist ein Anbieter-Update ein Risiko. Mit Evals ist es ein kontrollierbares Ereignis.
Systematische Evals schonen Ihre Experten-Ressourcen und beschleunigen den Go-live. Ein proaktives Verständnis der Systemdynamik verkürzt die Zeitspanne von der Entwicklung bis zur Marktreife (Time-to-Market) massiv.
Die interne Diskussion verändert sich ebenfalls. Statt „das System verhält sich manchmal komisch“ gibt es konkrete Zahlen: Retrieval-Qualität auf Testfragenset X, Halluzinationsrate in Kategorie Y, Token-Verbrauch pro Anfrage Z. Das verschiebt Gespräche mit Stakeholdern von Bauchgefühl zu Steuerungsinformation. Für die Geschäftsführung bedeutet dieses Bewusstsein den entscheidenden Vorsprung: Es geht darum, die Effizienzsteigerung in Unternehmen durch KI nicht dem Zufall zu überlassen, sondern sie durch professionelles Engineering steuerbar zu machen.
RAG + AI-Evals erhöhren Transparenz und Qualität
SMADEV unterstützt Sie dabei, diese technologischen Herausforderungen nicht als Barrieren, sondern als exklusive Chance zur Wertschöpfung zu nutzen. Indem wir die Dynamik von RAG-Systemen als beherrschbare Prozesskette definieren, legen wir den Grundstein für eine KI-Lösung, die nicht nur technisch überzeugt, sondern einen harten und messbaren ROI liefert.
Wer seine RAG-Pipeline versteht, senkt Entwicklungskosten und vermeidet teure Überraschungen im Betrieb. Unternehmen, die Retrieval-Qualität und Token-Verbrauch aktiv messen, steuern ihre KI-Investition, alle anderen verwalten sie.
Erfahren Sie mehr über unsere Methodik:
Unser AI-Evals-Ansatz übersetzt komplexe Datenarchitekturen systematisch in wertschöpfende, steuerbare KI-Produkte.
Lassen Sie uns den nächsten Schritt gemeinsam gehen.
Steht Ihr RAG-System vor dem Go-live oder läuft es bereits und Sie fragen sich, ob die Qualitätssicherung hält was sie verspricht?
Jetzt kostenfreies Strategiegespräch vereinbaren und konkreten Nutzen für Ihr Unternehmen prüfen
Das Problem liegt meist nicht im Sprachmodell, sondern davor. Falsches Chunking zerschneidet relevante Informationen so, dass kein einzelnes Fragment die Antwort vollständig enthält. Fehlende Metadaten verhindern gezieltes Filtern. Veraltete Dokumente ohne Versionierung liefern korrekt klingende, aber längst überholte Antworten. Das Modell halluziniert nicht, es arbeitet mit dem, was das Retrieval ihm gibt.
Die häufigsten: schlechte Datenqualität im Quelldokument (Duplikate, Widersprüche, veraltete Inhalte), falsches Chunking (zu groß oder zu klein), fehlende oder inkonsistente Metadaten, ein Systemprompt der mit abgerufenen Fragmenten kollidiert, sowie Index-Updates ohne anschließende Retrieval-Tests. Jede Fehlerquelle erzeugt andere Symptome und braucht eigene Testabdeckung.
Die Fehlerquellen in einer „Black-Box RAG“ sind vielfältig und oft unsichtbar (Silent Failures):
Ja, bei stabilem Index, stabilem Embedding-Modell und stabilen Parametern ist Retrieval reproduzierbar. Andere Ergebnisse bei gleicher Frage entstehen nur nach einem Index-Update oder Modell-Wechsel. Deshalb sind Index-Updates die kritischen Ereignisse, nach denen Retrieval-Tests erneut laufen müssen. Die nicht-deterministische Komponente im System ist ausschließlich das LLM.
Bestehende Vektoren behalten ihre Position im Vektorraum. Neue Dokumente erweitern den Suchraum, sie verschieben nichts. Was sich ändert: Bei bestimmten Abfragen können neu hinzugefügte Dokumente jetzt relevanter erscheinen als bisher abgerufene Fragmente. Das kann gewollt sein oder ein Problem, wenn veraltete Inhalte nicht entfernt wurden.
Hier wird nach Dimensionen unterschieden. Je nach Use Case sind diese unterschiedlich gewichtet, dabei ist nicht jede Dimension immer gleich relevant. Zu ihnen gehört: Antwort & Outcome, Grounding & Wissen, Agent & Tooling, Conversation und Operational Quality.
Spätestens bevor ein RAG-System in Produktion geht. Ohne Evals merkt man Qualitätsverluste erst, wenn Nutzer sie melden, zu dem Zeitpunkt hat das System bereits Vertrauen verbraucht.
Die Kosten: erneute Entwicklungszyklen, ungeplante Hotfixes, und im schlimmsten Fall ein System das intern als unzuverlässig gilt und nicht genutzt wird. Ein Testfragenset mit 50 bis 100 Fragen und definierten Referenzantworten ist der minimale Einstieg und lässt sich in einem Sprint aufbauen.
Künstliche Intelligenz ist gekommen, um zu bleiben, doch der Großteil der KI-Projekte leider nicht. Trotz hoher Erwartungen, teurer Tools und motivierten Teams schaffen es viele Vorhaben nie über die Konzeptphase hinaus. Ihnen fehlt das, was jedes erfolgreiche Projekt benötigt: Eine klar definierte strategische Ausrichtung.
In diesem Beitrag erfahren Sie, warum der Use-Case selbst entscheidend für den weiteren Verlauf Ihres geplanten KI-Projektes ist.
Viele Unternehmen starten ihre KI-Initiativen mit hoher Dynamik: Es werden Workshops durchgeführt, Daten analysiert und erste Prototypen entwickelt. Die Whiteboards füllen sich mit Konzepten zu Big Data und KI, die Präsentationen wirken überzeugend und dennoch kommt das Projekt unerwartet zum Erliegen. Es fehlen ein präzise definiertes Ziel, konkrete nächste Schritte und ein klar erkennbarer Mehrwert. Zurück bleibt lediglich ein digitales Artefakt: ein ansprechender Prototyp in der Schublade und der Eindruck, dass das Projekt deutlich mehr Potenzial gehabt hätte.
Was sind typische Gründe, warum KI-Projekte scheitern?

Ein KI-Projekt ohne klaren Use Case ist wie ein Algorithmus ohne Parameter: Er läuft, aber findet keine Lösung. Erfolgreiche KI-Projekte starten nicht mit der Technologie selbst, sondern mit einem konkreten, relevanten Problem.
Sie beginnen im operativen Alltag. Diese realen Herausforderungen sind der Ausgangspunkt, kein abstraktes Zukunftsversprechen oder ein neues gehyptes Tool. Anschließend folgt der nächste Schritt: die Übersetzung des Problems in einen greifbaren Use Case.
Doch ein Use Case allein genügt nicht. Er muss durch einen messbaren Mehrwert ergänzt werden. Erfolgreiche KI-Projekte setzen sich deshalb klare, überprüfbare Ziele, beispielsweise: „Reduktion der Bearbeitungszeit um 40 % innerhalb von sechs Monaten.“ Das ist der Unterschied zwischen einem Experiment und einer echten Initiative.
Praxis-Tipp: Fragen Sie sich zu Beginn:
„Würden wir dieses Projekt auch starten, wenn es keine KI wäre, weil das Problem wichtig ist und gelöst werden sollte?“
Die Suche nach dem passenden KI-Use Case beginnt nicht im Rechenzentrum, sondern mit einem offenen Ohr im eigenen Unternehmen. Die besten Ansätze liegen oft direkt vor der Nase, in Prozessen, die regelmäßig haken, in Aufgaben, die zu viel Zeit kosten, oder in Entscheidungen, die auf Bauchgefühl statt Daten basieren.
Wie findet man sinnvolle KI-Use Cases?
Doch hier wird es spannend: Nicht jedes Problem ist automatisch ein KI-Use Case.
Und nicht jede Idee ist umsetzbar, zumindest nicht sofort.

Die Folge ist der Übergang vom Bauchgefühl zur Struktur: Das Problem wird konkretisiert, der Nutzen geschärft und erste Erfolgsindikatoren werden abgeleitet. Beantwortet wird zudem die Frage, ob sich KI an sich lohnen würde.
Weitere essenzielle Fragen, die wir bei der SMA Development mit unseren Kunden anschließend beantworten sind:
Teil 2 dieser Reihe: „Warum Technologie selten das Problem ist, aber Daten es fast immer sind!„
Jetzt komplettes Whitepaper mit 6-Schritte-Plan kostenlos downloaden!
Alles auf einem Blick. Was erfolgreiche KI-Projekte ausmacht und warum andere scheitern!
