LLM Evaluation Methoden: AI-Evals für KI-Qualität | SMADEV
Die Herausforderungen in KI-Projekten verschieben sich drastisch: Wir sprechen nicht mehr von Systemabstürzen, sondern vom sogenannten „Silent Failure“. Anwendungen liefern technisch einwandfreie Datenpakete aus, während der inhaltliche Kern zu halluzinieren beginnt, Compliance-Richtlinien verletzt werden oder die Markenreputation durch einen falschen Tonfall gefährdet wird. Technisch gesehen ist das System ein Erfolg. Der Live-Betrieb liefert jedoch andere Daten, z. B. faktisch falsche Auskünfte oder fehlerhafte Zusammenhänge aus Kundendaten, Projektständen oder Wissensquellen. Ob dies geschäftsschädigend sein wird, ist nicht die Frage, sondern wann. Welcher Aspekt macht KI-Systeme also robust genug gegen deren typische probabilistische Eigenschaften (ein Input, variierende Outputs)?
Nach diesem Beitrag werden Sie verstehen, warum KI-Qualität keine Frage von herkömmlichen Softwaretest darstellt und was stattdessen die logische Ergänzung zu diesen Tests sein muss, damit auch ein LLM sauber überwacht werden kann.
In der modernen Software-Architektur müssen wir heute zwei völlig unterschiedliche Welten gleichzeitig beherrschen: den Determinismus des Codes und die Probabilistik des LLMs.
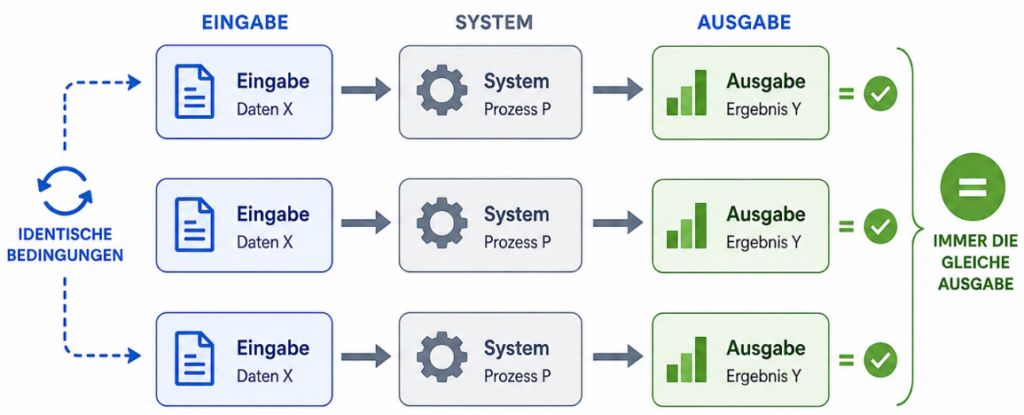
Determinismus: Ein System ist deterministisch, wenn eine bestimmte Eingabe unter identischen Bedingungen immer zur exakt gleichen Ausgabe führt.
Betrachtet als Außenschicht (Das deterministische Skelett): Hier gelten die alten Regeln der Software-Exzellenz. Wir testen API-Endpunkte, JSON-Validierungen und Rate-Limiting.
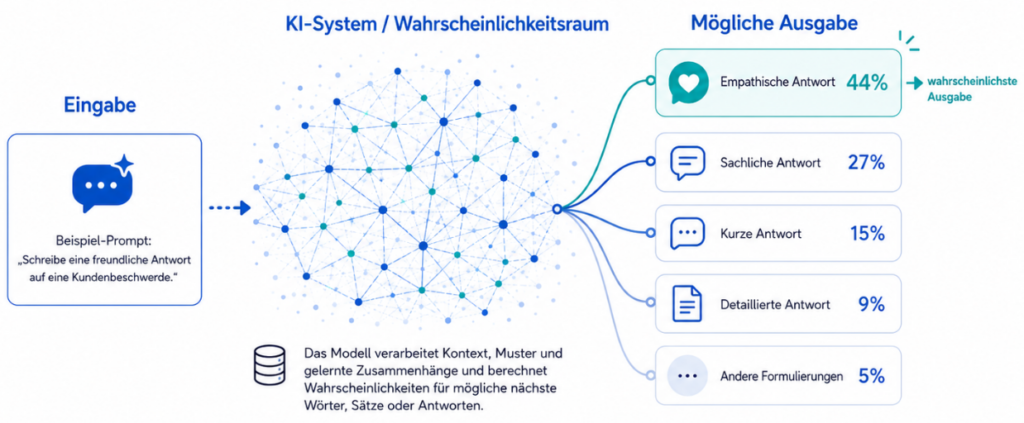
Probabilistik: Ein System (KI) ist probabilistisch, wenn das Ergebnis auf statistischen Wahrscheinlichkeiten beruht. Die Ausgabe ist nicht fixiert, sondern das Resultat der „wahrscheinlichsten“ Antwort in einem riesigen Datenraum.
Betrachtet als Innenschicht (Der probabilistische Kern): Hier arbeitet das LLM. Da Sprachmodelle auf Wahrscheinlichkeiten basieren, liefern sie bei identischem Input variierende Outputs. Genau diese Herausforderungen lassen sich messen und steuern, um KI-Qualität zu gewährleisten.
Welchen zusätzlichen Faktor brauchen KI-Systeme?
Wer KI-Systeme ausschließlich mit den deterministischen Methoden der klassischen Softwareentwicklung testet, sichert zwar das „Skelett“ der Anwendung, überlässt aber die Qualität der LLMs dem Zufall. Hier setzen AI-Evaluations an. Sie bilden die Basis, um die Qualität von LLMs messbar und steuerbar zu machen.
Was sind AI-Evals?
AI-Evaluations sind ein systematisches Framework, um die Güte, Sicherheit und Verlässlichkeit von KI-Outputs messbar zu machen. Sie liefern keine binäre Antwort wie „Richtig“ oder „Falsch“, sondern einen Score, z. B. zwischen 0.0 und 1.0.
AI-Evaluations sind keine Alternative, sondern eine Ergänzung zu klassischem IT-Testing. Während deterministische Tests die Stabilität garantieren, sichern probabilistische Evals die Qualität der KI und damit die geschäftliche Verwertbarkeit dieser Investition.
Was messen AI-Evals?
Je nach Use Case werden bestimmte Dimensionen unterschiedlich gewichtet d.h. nicht jede Dimension ist immer gleich relevant.
- Antwort & Outcome
- Grounding & Wissen
- Agent & Tooling
- Conversation
- Operational Quality
Wie wird gemessen?
Nicht jede Methode passt in jede Phase des AI-Evaluations Prozesses. Entscheidend ist der gezielte Einsatz. Beispiele sind:
- Trace Review (Human)
- Persona Simulation
- Gold Sets / Benchmarks
- Versionsvergleich
- Persona Simulation
- Synthetic Generation
- Live Monitoring Signals
- LLM-as-Judge
Beispiele, in denen AI-Evals zur Konsequenz wurden
KI-Assistenzsystem für Service-Techniker (Reparaturanweisung): Das Modell halluziniert bei einer spezifischen Drehmoment-Angabe für ein kritisches Bauteil, weil es zwei ähnliche Handbuch-Versionen vermischt. 📉
- Bauteilversagen im Betrieb
- Haftungsfragen und bürokratischer Aufwand
- Vertrauensverlust in KI-Lösungen
Marge im B2B-Vertrieb (KI-Agent unterstützt bei komplexen Rahmenverträgen und Pricing-Optionen für Großkunden): Durch eine schleichende Qualitätsminderung (Model Drift) beginnt die KI, Rabattkombinationen vorzuschlagen, die zwar logisch klingen, aber die internen Profitabilitäts-Leitplanken subtil unterwandern oder veraltete Konditionen heranziehen. 📉
- suboptimale Margen
- Schaden fällt erst Monate später auf
- Herkömmliche IT-Sicherung scheitert
Fehlsteuerung in der Logistik-Optimierung (KI-Decision-Support für Kapazitätsplanung basierend auf historischen Mustern und Echtzeitdaten): Die KI erkennt ein Muster in den Daten falsch (Korrelation vs. Kausalität) und schlägt eine Umleitung vor, die die Engpässe tatsächlich verschlimmert, anstatt sie zu lösen. Die KI ist sich ihrer Sache „sicher“, aber die statistische Basis ist instabil.
- Massive operative Verzögerungen
- Direkter Einfluss auf die Key Performance des Unternehmens
- Data-to-Value wird zu Data-to-Loss
Die Erkenntnis, AI-Evals als logische und notwendige Ergänzung zu betrachten, vermittelt den Übergang von einer rein technischen zu einer strategischen Steuerung: Man muss die Qualitätssicherung der eigenen KI-Infrastruktur neu evaluieren. Es reicht nicht mehr aus, die „Funktionalität“ abzufragen. Man muss die „Validität der KI“ als KPI in die Management-Dashboards integrieren. So steuert man ein experimentelles Pilotprojekt in ein skalierbares, auditierungsfähiges Enterprise-Asset.
Investitionen nur in die Entwicklung von KI-Features sind zu kurz gedacht; beachtet werden muss ebenfalls die Validierungskette. Nur wer diese Dualität beherrscht, sichert den entscheidenden Marktvorteil: die Transformation von „Research“ in messbaren „Revenue“ bei voller Risikokontrolle.
Welche wirtschaftlichen Vorteile bringen AI-Evals?
Der Einsatz von AI-Evals (systematische Evaluation von KI-Modellen und -Anwendungen) wird oft als technischer Zusatzaufwand gesehen, ist aber neben den Hauptfaktoren für erfolgreiche KI-Projekte (Hier mehr erfahren) wirtschaftlich einer der größten Hebel für den Erfolg eines KI-Projekts.
Massive Senkung der Betriebskosten (OpEx)
- Vermeidung von Fehlentwicklungen
- Modell-Optimierung
- Reduzierung manueller Nacharbeit
Risikominimierung und Schutz des Markenwerts
- Vermeidung von Haftungsrisiken
- Schutz vor Reputationsverlust
- Compliance (EU AI Act)
Beschleunigter Time-to-Market
- Schnellere Iterationszyklen
- Confidence to Deploy
Höhere Customer Lifetime Value (CLV) & Conversion
- Bessere Nutzererfahrung
- Wettbewerbsvorteil
- Kapitaleffizienz durch Skalierbarkeit der Qualitätssicherung
Optimierung der Infrastruktur (RAG-Effizienz)
- Wenn Sie Retrieval Augmented Generation (RAG) nutzen, helfen Evals dabei, genau die Dokumente zu finden, die den größten Nutzen stiften. Sie vermeiden es, unnötig viele Daten zu verarbeiten, was die Latenz verringert und die Rechenkosten senkt.
KI-Qualität wird nicht nur zur harten Markteintrittsbarriere, sondern auch zum Skalierungsfaktor! Aber nicht für Sie.
Jetzt Whitepaper herunterladen
Von der Theorie zur Praxis: Systematische AI-Evaluations verstehen.
Entdecken Sie, wie Sie AI-Qualität messbar machen: vom Konzept bis zur Implementierung.

Wenn Sie wissen möchten, wie AI-Evals auch für Sie und Ihr KI-System funktionieren können, dann vereinbaren Sie ein unverbindliches Erstgespräch. Kein Druck, kein Verkaufsgespräch, sondern ein ehrlicher Austausch Ihrer Situation und den Stand Ihrer KI-Anwendung.