LLM-Halluzinationen: Korrekte Daten lösen das Problem nicht
Ein KI-System hat die AGB Ihres Unternehmens vollständig geladen. Es kennt jeden Paragraphen. Und trotzdem verspricht es einem Kunden eine Leistung, die rechtlich nicht gedeckt ist. Das passiert täglich in Systemen, die längst als produktionsreif gelten.
Der Grund liegt nicht im fehlenden Datenzugriff. Er liegt darin, wie das Modell mit den Daten umgeht.
Was ist eine LLM-Halluzination?
Der Begriff täuscht. „Halluzinieren“ klingt nach einem Defekt, nach etwas, das nicht hätte passieren dürfen. Präziser ist der Begriff Konfabulation: Das Modell erfindet keine Antwort, weil es fehlerhaft ist. Es vervollständigt einen Satz auf Basis statistischer Wahrscheinlichkeiten aus seinem Training und diese Vervollständigung klingt kohärent, grammatisch korrekt und überzeugend. Genau das macht sie gefährlich.
Das Modell berechnet, welches Wort als nächstes wahrscheinlich kommt. Wenn die Trainingsdaten für ein bestimmtes Thema dünn, widersprüchlich oder schlicht falsch waren, produziert das Modell trotzdem eine Antwort, eine, die sich nicht von einer richtigen unterscheiden lässt. Keine Unsicherheitsmarkierung, kein Zögern.
Zwei Fehlerklassen, zwei verschiedene Lösungen
Die Forschung unterscheidet heute präziser als noch vor zwei Jahren. Diese Unterscheidung ist relevant, weil sie bestimmt, welches Problem Sie lösen müssen.
Faktuelle Halluzinationen entstehen, wenn ein Modell Dinge erfindet: Gerichtsurteile, Produktversionen, historische Ereignisse. Ursachen sind fehlender Datenzugriff, ein veraltetes Training-Cutoff-Datum oder fehlerhafte Trainingsdaten. Diese Kategorie lässt sich durch RAG-Architekturen deutlich reduzieren. Wer dem System strukturierte, aktuelle Quellen zur Verfügung stellt und den Zugriff technisch erzwingt, schließt dieses Risiko weitgehend. Eine Studie aus 2025 zeigt die Richtung: Die Halluzinationsrate sank von 21,3 % auf 8,5 % durch RAG-Integration mit Governance-Modul.
Logische Halluzinationen sind das schwierigere Problem. Das Modell hat korrekte Fakten vorliegen. Es zieht trotzdem die falsche Schlussfolgerung. Ein Bot liest die AGB, erkennt den Sonderfall des Kunden falsch und leitet daraus eine Aussage ab, die inhaltlich plausibel klingt, aber rechtlich nicht haltbar ist. Diese Fehlerklasse lässt sich nicht durch bessere Datenanbindung lösen.
Drei Mechanismen, die Halluzinationen konkret auslösen
Wer versteht, wie Halluzinationen entstehen, kann gezielter gegensteuern. Drei Mechanismen sind in der Praxis besonders relevant.
Optimierung auf Zustimmung statt Wahrheit. Modelle werden durch RLHF und RLAIF auf Hilfsbereitschaft trainiert. Das Problem: RLHF optimiert auf menschliche Bewertungen und Menschen bevorzugen in Evaluierungen häufig Antworten, die zustimmend und kohärent klingen, nicht Antworten, die Unsicherheit signalisieren. Wenn ein Nutzer hartnäckig auf einen Rabatt besteht, tendiert ein so trainiertes Modell dazu, die gefragte Aussage zu produzieren, auch wenn die Quelldaten sie nicht decken. Das Modell halluziniert in diesen Fällen nicht aus Unwissenheit, sondern weil falsch gesetzte Trainingsanreize Gefälligkeit über Genauigkeit stellen.
Kontextrauschen bei widersprüchlichen Informationen. Selbst mit großen Kontextfenstern gilt: Wenn Informationen im Prompt widersprüchlich sind oder sich gegenseitig überlagern, wählt das Modell auf Basis statistischer Gewichtung, nicht auf Basis faktischer Korrektheit. Es zieht diejenige Information vor, die in seinen Trainingsdaten am stärksten verankert ist. Das ist besonders relevant, wenn interne Dokumente veraltet oder inkonsistent sind, ein häufig unterschätztes Problem in produktiven Systemen.
Grounding-Lücke zwischen Generierung und Faktenprüfung. In hybriden Architekturen, die einen sprachgenerierenden Teil mit einer regelbasierten Validierungsschicht kombinieren, entstehen Halluzinationen besonders an deren Schnittstelle. Wenn ein Nutzer durch sehr hartnäckiges Nachfragen Druck aufbaut „Bist du sicher? Ich brauche das jetzt!“ oder ein Prompt-Injection-Angriff erfolgreich ist, kann das die Validierungsschicht in bestimmten Szenarien umgehen. Das Ergebnis: eine Antwort, die die Faktenprüfung formal passiert hat, aber inhaltlich nicht haltbar ist.
Was daraus folgt für die Systemarchitektur
Bevor RAG zum Standard wurde, versuchte man, LLMs durch kontinuierliches Training mit spezifischen Daten neues Wissen beizubringen. RAG erwies sich jedoch für diesen Zweck als deutlich effizienter. Das Fine-Tuning hat heute trotzdem seine Anwendung und andere Aufgaben.
Fine-Tuning formt, wie ein Modell spricht, RAG bestimmt, worüber. Beides zusammen löst das Halluzinationsproblem trotzdem nicht vollständig: Faktische und logische Korrektheit brauchen verschiedene Lösungsebenen.
Wo Fragen entstehen können:
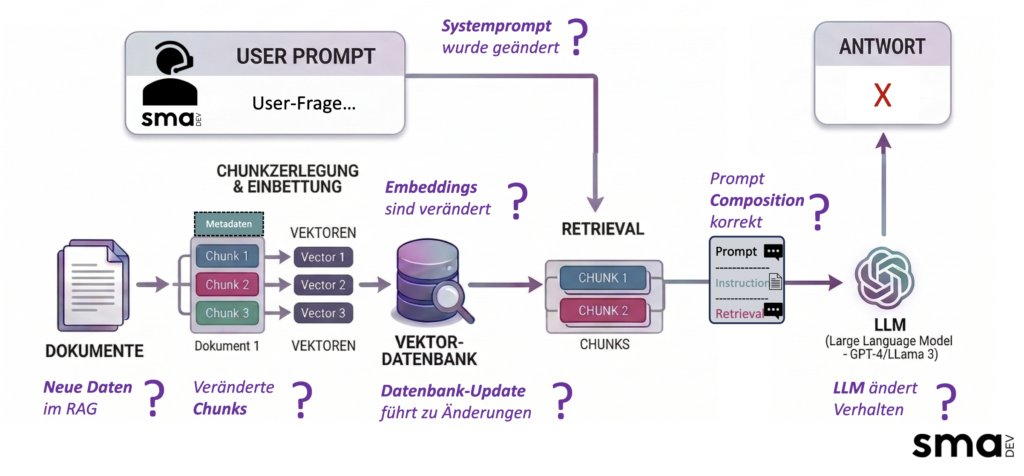
Entscheidend ist die Datenqualität vor der Retrieval-Schicht. Forschungsergebnisse aus 2025/2026 sind dazu eindeutig: 95 % der Enterprise-RAG-Fehler entstehen nicht im Modell, sondern in der Kontextschicht, durch veraltete, widersprüchliche oder schlecht klassifizierte Quelldaten. Wer hier nicht investiert, optimiert am falschen Ende.
Red Teaming gehört vor den Go-live. Seit 2025 belegen Studien systematisch, dass Halluzinationen provozierbar und messbar sind. Wer ein produktives System ohne dokumentierte Adversarial-Tests betreibt, schafft ein Risiko, das sich quantifizieren und juristisch zurechnen lässt. Das Argument „Die KI hat das halt so gemacht“ gilt als Haftungsbegründung nicht mehr.
Die People-Dimension entscheidet über die Adoption. Technisch robuste Guardrails scheitern dort, wo niemand im Unternehmen versteht, wann und wie das System versagt. Wer KI in Kundenprozesse integriert, braucht Teams, die Fehlermuster erkennen, nicht nur Dashboards, die sie melden.
Welche dieser Ebenen ist in Ihrem System heute adressiert und welche nicht? Das lässt sich in einem einstündigen technischen Review konkret herausarbeiten.